
Introduction
A clinical AI assistant deployed in a healthcare workflow surfaces a response containing fabricated medical guidance. When the compliance team investigates, they find no record of the exact prompt sent, which model version processed it, or which clinician triggered the request. Root cause analysis becomes impossible. Regulatory response stalls. The organization faces exposure under HIPAA's technical safeguard requirements. Not because the AI failed, but because the audit trail never existed.
This scenario reflects a fundamental gap in how enterprises approach LLM governance. Traditional application logging, designed for deterministic, structured systems, fails when applied to generative AI. LLMs produce probabilistic, unstructured outputs that can trigger real-world actions across healthcare, finance, and regulated operations.
Research shows that identical prompts yield divergent outputs depending on model version, temperature settings, and infrastructure variables. Without purpose-built audit logging, organizations cannot reconstruct decisions, demonstrate compliance, or respond to incidents before exposure accumulates.
In early 2025, the SEC fined 12 firms over $63 million for recordkeeping failures involving electronic communications, a precedent that extends to AI-assisted workflows. As 62% of enterprises experiment with AI agents and multi-step autonomous systems, the logging challenge compounds: more decision points, more autonomy, and still no standard for what gets captured. What follows breaks down exactly what to track, how to structure logs for both operational and regulatory use, and where manual approaches break down. Trussed is built to close these gaps from end to end.
Key Takeaways
- Effective LLM audit logs capture identity, model configuration, policy events, and cost attribution, not just inputs and outputs
- Agentic systems require step-level logging with shared trace IDs across every tool call and decision
- PII detection and masking must occur at log time to avoid creating new compliance liabilities
- One log infrastructure should serve both operational debugging and regulatory compliance, separate systems create gaps
- Trussed generates audit trails automatically at interception time, removing the need for manual log instrumentation in application code
Why LLM Audit Logging Is Different From Traditional Logging
Traditional logging assumes determinism. An API call with identical parameters returns the same result, database transactions follow predictable rules, and application logs capture discrete, repeatable events. LLMs violate every assumption.
The Determinism Gap
A 235-billion parameter model at temperature 0.0 (theoretically maximizing consistency) produced 80 unique completions across 1,000 identical runs due to batch variance effects. Major model providers have documented random anomalies in outputs caused by miscompiled sampling algorithms affecting specific batch sizes.
The same user input can produce different outputs depending on model version, system prompt, retrieval context, temperature settings, or infrastructure state. Standard access logs capture none of this context, which means incidents become nearly impossible to reconstruct without a platform like Trussed in place.
Scale and Multi-Provider Complexity
88% of organizations report regular AI use in at least one business function, and 37% of enterprises deploy five or more models simultaneously in production. These systems process text, documents, images, and structured data across multiple providers, often within a single workflow.
Traditional logging frameworks built for single-stack applications cannot track this distributed, multi-modal environment. Trussed unifies audit logging across every model and provider in use, so visibility does not fragment as the stack grows.
The Accountability Gap
The AI Incident Database has collected over 1,200 reports of intelligent systems causing real-world problems. Industry guidance consistently identifies "fragmented logging across distributed infrastructure" as a primary barrier to monitoring deployed AI systems.
Without logs that capture model version, retrieval context, policy evaluation, and decision chain, organizations cannot reconstruct incidents or demonstrate governance to regulators. Trussed captures each of these dimensions by default at the proxy layer.
The Core Categories of What to Track in LLM Audit Logs
Effective LLM audit logging covers five distinct categories. Each serves a different governance function. Skipping any one creates a specific blind spot. Trussed enforces capture across all five categories automatically.

Identity and Session Context
Identity context is the foundation of any audit. Without it, logs cannot answer "who did what." Trussed records:
- User ID, session ID, and authentication method
- Application or agent that initiated the request
- Timestamp and whether the caller was a human or system identity
That last point matters more than it seems. In automated pipelines where agents trigger LLM calls without direct human oversight, the audit trail must identify which agent, workflow, or service account made the request. When investigating an incident, the first question is: did a human operator ask for this, or did a system generate it autonomously?
Prompt, Response, and Retrieval Context
Trussed records:
- Full system prompt and user prompt
- Retrieved documents or chunks (in RAG architectures)
- Complete model response and any tool calls triggered
Retrieval context is critical for debugging hallucinations and policy violations. If an LLM fabricates information, the audit trail must show which documents were retrieved and whether they actually supported the output.
The tradeoff: storing raw content versus hashed or tokenized versions affects both compliance and forensic usefulness. Hashes verify integrity but prevent content reconstruction. If regulators require reviewing what was actually said, full content (with PII masked) must be retained. Trussed handles masking at log time so retained content stays compliant.
Model and Configuration Metadata
Trussed records:
- Model name, version, and provider
- Temperature and other inference parameters
- Token counts (input and output) and latency
Model version matters because the same prompt behaves differently across versions. Temperature settings directly modulate output randomness. Lower values favor likely predictions, higher values increase variability. This metadata is what makes incidents reproducible and explainable after the fact.
Policy, Safety, and Anomaly Events
Trussed records:
- Triggered guardrails and safety filters
- Policy rule violations and flagged content categories
- Override and escalation events
These events matter most to regulators and incident responders. They're the exception log auditors go straight to. When a guardrail blocks a PII-laden request, when a cost threshold fires an alert, when a human overrides an automated decision, each of these must be logged as a first-class audit record, not an afterthought.
Cost and Token Attribution
Trussed records:
- Token usage per request and estimated cost
- Attribution to team, application, model, and user
Cost attribution is a governance issue. Uncontrolled token consumption can signal misuse, prompt injection attempts, or runaway agent loops. Organizations need real-time visibility into where AI spend is going by business unit, project, and provider, not monthly reconciliation after budgets have already blown past.
Capturing these five categories consistently across every LLM interaction is the baseline requirement. The harder challenge is enforcing that requirement at scale, across multiple models and teams, without burdening application developers with manual instrumentation. Trussed sits on top of existing logging infrastructure and enforces audit policies at the proxy layer, ensuring every request is captured against these categories automatically, regardless of which model or provider is called.
Logging for Agentic AI and Multi-Step Workflows
Agentic systems create a fundamentally harder logging problem. Unlike a single-turn LLM call, an agent may execute dozens of steps, calling tools, reading databases, writing outputs, spawning sub-agents, before a human sees any result. A single entry-point log captures nothing meaningful.
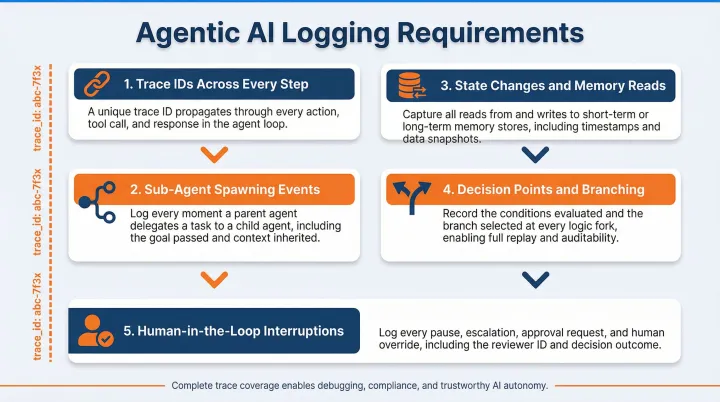
To reconstruct what actually happened across a workflow, you need event-level granularity tied together by a shared identifier. At minimum, agentic logging in Trussed covers:
- Trace IDs across every step: Each tool call gets its own log event, linked by a shared trace ID back to the originating request. Trussed captures the tool name, input parameters, response payload, latency, and any errors, not just the final output.
- Sub-agent spawning events: When an agent spawns a child agent, Trussed logs the delegation event separately, including which parent initiated it, what instructions were passed, and what the sub-agent returned.
- State changes and memory reads: If your agent reads from or writes to external memory or a database, Trussed logs those operations with timestamps. Unexplained state mutations are one of the hardest issues to debug retroactively.
- Decision points and branching: When an agent selects between multiple paths or tool options, Trussed logs the choice made and the reasoning if available. This is critical for audit trails in regulated environments.
- Human-in-the-loop interruptions: Any pause for human review, approval, or override is recorded as a named event in the log, including who reviewed it, when, and what action they took.
Without this level of detail, diagnosing a failure in a 20-step workflow often means starting from scratch. Trace-linked, step-level logs from Trussed let your team isolate exactly where a workflow went off course, whether that's a malformed tool call at step 3 or a policy violation triggered at step 17.
Agentic workflows amplify every logging gap that exists in single-turn systems. The same five core categories apply, but must now be captured at every step of every agent chain. Trussed enforces audit policies across agentic pipelines by intercepting each step at the proxy layer, attaching shared trace IDs automatically, and applying the same governance rules that cover standard LLM calls, extended to sub-agent spawning events, tool calls, and human-in-the-loop interruptions.


