
Introduction
Worldwide AI spending is forecast to reach $2.52 trillion in 2026, while Gartner's earlier GenAI forecast put 2025 GenAI spending at $644 billion. Together, those figures show how quickly AI budgets are scaling. Yet many enterprises still miss AI infrastructure forecasts, and a meaningful share report gross margin pressure tied to AI workloads. Finance and engineering teams are confronting the same core problem: AI deployment costs are unpredictable, unattributable, and often invisible until the bill arrives.
AI cost visibility is becoming a board-level issue. Recent survey coverage shows that many businesses still lack a clear, comprehensive understanding of their total AI costs - a gap that widens as deployments scale.
The ROI gap is real. Most organizations take two to four years to achieve satisfactory returns on a typical AI use case, and many organizations report limited measurable AI value despite substantial investment.
Poor decisions, insufficient visibility, and absent governance are what turn manageable costs into budget overruns. This guide examines three dimensions of cost reduction: upfront decisions that set cost structures, ongoing management that prevents runtime waste, and contextual factors that amplify or reduce spending across the AI lifecycle.
Key Takeaways
- AI deployment costs span compute, inference, data, talent, and compliance, and they stay hidden until scale makes them unavoidable
- Idle GPUs, unmanaged token consumption, and missing runtime spending controls drive more cost than the models themselves
- Cost reduction starts with better decisions at use case selection and model choice, not just infrastructure tuning after deployment
- Operational visibility, knowing which teams, models, and applications drive spend in real time, is a prerequisite for meaningful optimization
- Sustainable AI cost governance requires aligning engineering, finance, and operations around shared accountability
How Costs Around AI Deployment Typically Build Up
AI deployment costs do not arrive as a single upfront expense. They accumulate across phases, including experimentation, staging, and production, each adding new layers: compute provisioning, model serving, data storage, API usage, monitoring infrastructure, and ongoing retraining.
Enterprise AI implementations typically cost 3–5 times the initial proof-of-concept estimate when accounting for integration, customization, and operational overhead.
Cost build-up is both gradual and episodic. Costs grow steadily during normal operation, but can spike sharply during model training cycles, traffic surges, or agentic AI workflows where agent chains trigger cascading inference calls with compounding token accumulation. Agentic systems can accumulate meaningful per-decision costs depending on workflow complexity, which multiplies rapidly across thousands of daily interactions.
The most damaging costs in AI deployment are hidden until scale or failure exposes them:
- GPU idle time accrues charges whether or not workloads are actually running
- Context window bloat silently multiplies token costs as conversation histories get re-sent with each call
- Unmanaged API calls from autonomous agents accumulate with no visibility into cumulative spend
- Shadow AI usage across teams generates overruns that standard monitoring tools were never built to catch
A substantial share of AI-related cloud spend can go toward idle or underutilized resources, overprovisioned infrastructure, and poorly optimized workloads. GPU utilization during inference is often lower than expected in production environments, meaning hardware sits idle while accruing charges.
Agentic workflows make costs significantly harder to control. A single user request can trigger retrieval, planning, tool calls, validation, retries, and follow-up model calls - each adding tokens, latency, and spend. Teams need runtime attribution to see which agent, action, or workflow step actually created the cost.

Key Cost Drivers for AI Deployment
Compute: The Dominant Cost Category
Compute, specifically GPU utilization for training and inference, is the dominant cost category in most AI deployments. Because GPUs are priced regardless of utilization, underused or poorly scheduled GPU resources represent pure waste. The cost differential between GPU and CPU infrastructure can be substantial. High-end H100-based GPU instances from major cloud providers can cost dozens of times more per hour than general-purpose CPU instances, making utilization and workload placement central to AI cost control.
Production AI workloads frequently achieve under 50% GPU utilization, meaning organizations waste a significant portion of their GPU budget on idle resources. Recent infrastructure spending reports show that server hardware continues to dominate AI infrastructure investment, with rapid year-over-year growth tied to GPU-heavy workloads.
Token-Based Pricing: The Silent Cost Multiplier
Token costs compound faster than most teams expect. Because LLM APIs don't retain conversation history between calls, the full dialogue is re-sent with every request, multiplying token volume with each turn. Pricing changes frequently across model families and service tiers, but the pattern is consistent: higher-capability models, longer contexts, and uncached inputs cost more than smaller models, cached inputs, or batch processing.
In multi-turn conversations, resending the entire dialogue history causes token counts to snowball. A single API call costing a fraction of a cent can translate to $4,200 per day at a scale of 30,000 conversations. Intelligent context management, such as summarizing history rather than re-sending full transcripts, can cut token usage by 80–90% and improve response quality.
Model Selection: A Cost-Determining Decision
Routing every task to a frontier LLM, including work a smaller model handles just as well, is one of the fastest ways to inflate inference costs. The gap between model tiers is rarely marginal, and defaulting to the largest available model is rarely the right approach. Smaller or fine-tuned models can handle classification, retrieval, summarization, and structured output tasks at a fraction of the cost of frontier models, while meeting quality targets for those use cases.
Enterprises that reserve large frontier models for complex reasoning tasks and route simpler workloads to smaller models can cut inference costs substantially while maintaining output quality where it matters.

Absence of Cost Attribution: The Structural Problem
When no system tracks which team, application, or agent is generating AI spend in real time, overspending goes undetected until a cloud bill arrives. This lack of visibility delays corrective action and prevents cross-team accountability. Most organizations know their AI spend is rising. Almost none can tell you which team, workflow, or model is responsible for the increase.
Compliance Failures in Regulated Industries
In regulated industries, compliance failures introduce a distinct cost category: audit preparation overhead, remediation effort, regulatory fines, and the operational cost of managing policy violations after the fact. The penalties are severe:
- EU AI Act: Fines up to €35,000,000 or 7% of global annual turnover for prohibited AI practices
- HIPAA: Maximum annual penalties of $2,134,831 per violation category
Unlike infrastructure costs, compliance exposure scales with organizational risk, not just usage volume.
Cost-Reduction Strategies for AI Deployment
Strategies for reducing AI deployment costs vary depending on whether cost originates from decisions made before deployment, from how AI systems are governed while running, or from the broader infrastructure and organizational context surrounding them.
Strategies That Reduce Costs by Changing Decisions
These approaches reduce cost by altering choices made before or during AI deployment planning, including use case scope, model selection, service-level requirements, and prompt design policies.
Define Service-Level Requirements Before Selecting Infrastructure
Clarify the distinction between real-time and batch processing needs, tolerable latency thresholds, and average versus peak load requirements. Over-provisioning for responsiveness levels a use case doesn't require (treating a batch document analysis task like a real-time chatbot, for example) is one of the most common and avoidable sources of excess AI spend.
Apply a Tiered Model Selection Strategy
Match model capability to task complexity. Reserve large frontier models for complex reasoning tasks while routing classification, retrieval, summarization, and structured output tasks to smaller or fine-tuned models. The cost difference between model tiers at scale is substantial, and "biggest available model" is rarely the right default.
Adopt a Structured Build vs. Buy vs. Fine-Tune Decision Framework
The total cost of ownership (TCO) of a pre-trained model, a fine-tuned model, and a custom-built model diverge significantly across cost categories: training, inference, operations, and adapter layers. Choosing the wrong approach early locks in cost structures that are expensive to undo. Evaluate:
- Pre-trained models: Lower upfront cost, higher inference cost at scale
- Fine-tuned models: Moderate training cost, lower inference cost for specialized tasks
- Custom-built models: High training cost, full control over inference economics
Establish Token and Prompt Governance Policies at the Design Stage
Define maximum prompt lengths, manage context window usage, and set response verbosity standards before deployment, not after. This prevents token costs from compounding silently at scale. Policies should include:
- Maximum context window size per request
- Conversation history summarization thresholds
- Response length limits by use case
- Prompt template standardization
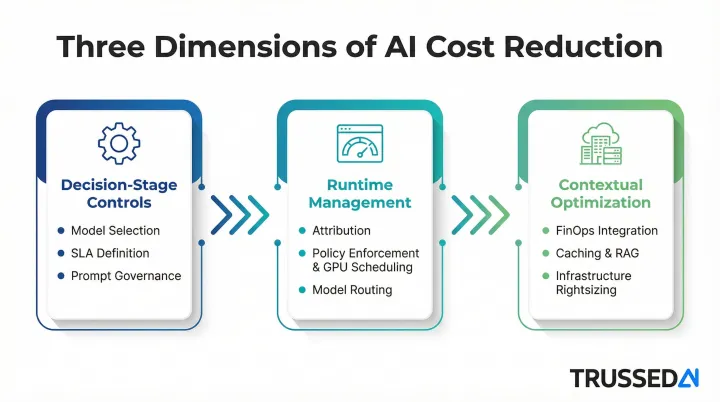
Strategies That Reduce Costs by Changing How AI Is Managed
These approaches reduce cost by improving control, visibility, and enforcement while AI systems are actively running, addressing waste, drift, and unaccountable usage as they occur.
Implement Real-Time Cost Attribution Across Teams, Models, and Applications
Cost visibility at the level of individual applications, agent workflows, and organizational teams is a prerequisite for any governance effort. Without attribution, engineering teams cannot identify which workloads are driving disproportionate spend, and finance teams cannot hold teams accountable. Platforms like Trussed AI provide real-time cost tracking and attribution as part of a unified AI control plane, enabling organizations to correlate spend with usage at runtime rather than after the bill arrives.
AI cost management is becoming a governance problem, not only a finance problem. Enterprises need runtime visibility into which applications, teams, models, and workflows are generating spend - and the ability to enforce policies before costs escalate. This is the role Trussed AI's control plane plays in production AI environments.
Enforce Policy-Based Spending Controls at the Point of Inference
Real-time policy enforcement prevents waste at the point it occurs. Configuring limits in a monitoring dashboard is not the same as enforcing them at inference time. Runtime enforcement stops overruns before they happen, not after. This includes:
- Hard stops that block requests exceeding budget thresholds
- Token limits per request, per user, per team
- Model access policies that restrict expensive model usage to approved use cases
- Automated alerts before thresholds are reached
Optimize Workload Scheduling to Eliminate GPU Idle Waste
GPUs accrue cost whether or not they are processing workloads. Scheduling AI jobs to minimize gaps between workloads, enabling auto-shutdown for idle instances, and batching non-urgent inference requests are operational practices that directly reduce compute spend without degrading output quality. Dynamic pooling and queue-based scheduling can meaningfully reduce infrastructure costs in documented deployments.
Apply Intelligent Model Routing and Fallback Logic in Production
Route requests dynamically to lower-cost models when query complexity does not warrant a frontier model, and maintain fallback paths that preserve quality while reducing cost. Intelligent routing is a runtime capability, not a design-time one, and requires active management. When implemented well, routing decisions happen transparently. Users see no degradation while costs drop.
Strategies That Reduce Costs by Changing the Context Around AI Deployment
These approaches reduce cost by addressing organizational practices, infrastructure architecture, and dependency choices surrounding AI systems. In many cases, the context is the primary cost driver.
Adopt FinOps as a Cross-Functional Organizational Discipline
AI cost management cannot be owned by engineering alone. FinOps is an operational framework that maximizes the business value of technology by creating financial accountability through collaboration between engineering, finance, and business teams. 98% of FinOps survey respondents now manage AI spend, reflecting the discipline's rapid expansion into AI workloads.
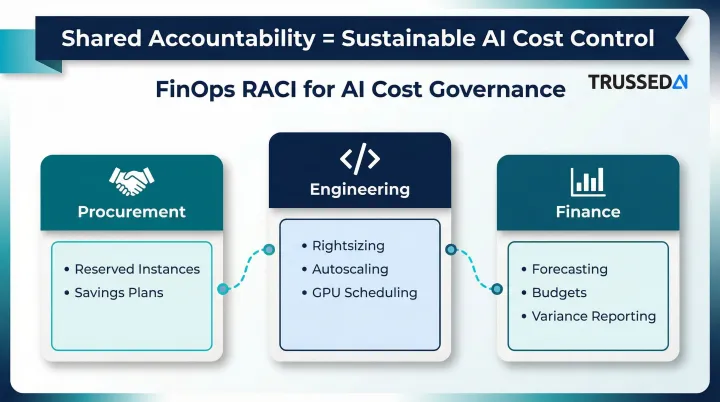
Treating cost as a post-deployment cleanup task produces reactive, unsustainable controls. Aligning teams around shared metrics and governance rituals from the start is what creates durable financial discipline. FinOps RACI models assign clear ownership:
- Procurement: Commits to reserved instances and savings plans
- Engineering: Handles rightsizing and autoscaling
- Finance: Owns forecasting methods and budgets
Use Caching and RAG Architectures to Reduce Redundant Token Processing
Caching repeated context or frequently accessed knowledge reduces the volume of tokens processed per request. Cached-input pricing varies by model and provider, but caching is a direct cost-control lever for repeated context, long prompts, and high-volume workflows - typically reducing input costs meaningfully compared to uncached processing. Prompt caching can also cut latency significantly alongside token cost reductions.
Retrieval-augmented generation (RAG) architectures complement caching by retrieving only relevant context rather than re-sending full conversation histories. For knowledge-intensive applications, this cuts inference costs directly. Semantic caching reduces API calls by up to 68.8% across various query categories.
Right-Size Infrastructure with Containerization and Workload Placement
Many inference workloads, particularly those running smaller models, can be served cost-effectively on CPU-based infrastructure using containerization, freeing expensive GPU resources for workloads that genuinely require them. CPUs can deliver viable inference throughput on optimized, smaller models, which is sufficient for applications like chatbots and document summarization.
Multi-cloud and hybrid deployment flexibility also allows organizations to place workloads where cost-to-performance ratios are most favorable. Spot instances provide access to spare compute capacity at savings of up to 90% compared to on-demand prices, though they can be interrupted with two minutes of notice. GKE and AKS support spot node pools with on-demand fallbacks for fault-tolerant workloads.
Conclusion
Controlling AI deployment costs starts with identifying where cost actually originates, whether at the decision point, at runtime, or in the surrounding context, then addressing those origins with targeted action. Organizations that manage AI costs effectively treat cost management as inseparable from governance, security, and operational control. You can't optimize what you can't see, and you can't govern what you can't attribute.
AI cost governance is strategic, contextual, and continuous. Organizations that build governance infrastructure, including real-time visibility, attribution, and policy enforcement, into their AI deployments from the start avoid the financial unpredictability that has made cost overruns a persistent concern for enterprise AI teams.
The shift from reactive monthly reconciliation to proactive, continuous cost control changes how teams plan, scale, and justify AI investment. Platforms like Trussed AI give enterprise teams the runtime visibility and attribution needed to make that shift without slowing deployment velocity.
Frequently Asked Questions
What are the 4 pillars of cost optimization?
The commonly referenced pillars are visibility (inform), rightsizing (optimize), accountability (allocate), and continuous governance (operate). In AI deployment, these translate to real-time cost tracking, intelligent model selection and workload placement, team-level spend attribution, and ongoing policy enforcement at runtime.
What is the biggest cost driver in AI deployment?
Compute, particularly GPU utilization for training and inference, is often the dominant cost category because high-end GPU instances can cost many times more than CPU alternatives. However, token consumption in generative AI workloads and the absence of real-time attribution can be equally impactful at scale, especially when conversation histories compound token usage.
How does token usage affect AI deployment costs?
Token-based pricing charges per 1 million tokens processed. Because most LLM APIs are stateless, conversation history is re-sent with every request, causing token counts to compound rapidly in multi-turn conversations. Context window size and prompt length translate directly into cost. At 30,000 conversations per day, a single misconfigured API call can reach $4,200 daily.
What is the difference between AI training costs and inference costs?
Training is a large, episodic upfront cost driven by sustained GPU compute and data storage. Inference is an ongoing, variable cost driven by every request served in production. Inference can become the majority of lifetime AI cost for production GenAI systems because every prompt, response, and agent action generates ongoing usage-based spend.
How can organizations track AI spending across teams and models?
Cost attribution requires tagging AI usage by team, application, and model at runtime. This requires purpose-built tooling, either within cloud platforms or through an AI control plane like Trussed AI, rather than relying on end-of-month billing reports. Real-time tracking lets teams correlate spend with usage as it happens.
What is FinOps for AI and how does it help control costs?
FinOps is a cross-functional discipline that aligns engineering, finance, and operations around shared cloud cost accountability. Applied to AI, it extends these practices to cover GPU utilization, token consumption, model-level spend, and inference load patterns. The result is continuous, enforceable governance, not a monthly reconciliation exercise.
Why are AI agent costs harder to control than standard LLM costs?
Standard LLM costs are usually tied to a prompt, response, model, and token count. AI agents can trigger multiple model calls, retrieval steps, tool calls, retries, and downstream actions from one user request. That makes runtime attribution essential - teams need to see which agent, workflow, model, and action created the spend.


