
Introduction
According to the 2025 State of AI Cost Management report, 80% of enterprises miss their AI infrastructure forecasts by more than 25%, with 84% reporting significant gross margin erosion tied to AI workloads. This isn't a minor budgeting error. It's a structural failure that constrains future AI investment and erodes executive confidence, particularly in regulated industries where cost predictability directly affects risk posture.
Unmanaged AI spend creates cascading operational problems. Finance teams can't forecast accurately, engineering teams operate without cost accountability, and executives start questioning whether AI initiatives deliver measurable value.
In healthcare, insurance, and financial Solution, the problem compounds further. Unpredictable AI costs complicate compliance reporting and budget planning, creating friction with regulators and slowing AI adoption timelines.
None of this is inevitable. Most runaway AI spend traces back to the same underlying failures: no visibility into where costs originate, no accountability for who generates them, and no governance layer enforcing limits before bills arrive. The sections below walk through practical strategies to fix each one, so you can bring AI spend under control without slowing down the teams building with it.
Key Takeaways
- Token usage, inference volume, and agentic call chains make AI costs invisible in standard cloud billing
- The core problem is invisibility. Most AI spend is buried in shared compute with no attribution to teams, products, or agents
- The biggest cost drivers are model misalignment, agentic call multiplication, missing attribution, and absent real-time governance
- Effective cost control spans three layers: before AI runs, while it runs, and structural changes to the environment it runs in
- High-maturity teams track cost per inference, attribute spend to teams and products, and tie it to business outcomes, not just total budget
How AI Costs Typically Build Up
AI costs do not arrive as a single visible expense. They accumulate across multiple parallel streams, including model inference calls, training and fine-tuning jobs, vector database queries, third-party API fees, and GPU compute, that are billed separately and often buried under generic cloud line items like compute or storage. Inference now dominates the AI budget, representing 85% of enterprise AI spending in 2026, driven by the shift from experimental chatbots to production-scale agentic deployments.
Cost build-up is both gradual and compounding. A modest inference cost per request multiplies rapidly as usage scales, and several mechanisms accelerate that growth simultaneously:
- Agentic workflows trigger cascading model calls, each carrying its own token charges
- Expanding context windows increase per-call cost with each interaction, even when behavior looks unchanged
- Multi-agent coordination adds tool call fees on top of base inference costs
A single user query that costs $0.02 in development can reach $0.50 in production once context history and agent orchestration are factored in.
That gap between development and production cost is where most budget surprises originate. Costs remain invisible until scale or a product launch stress-tests the system, and by then months of uncategorized spend have accumulated with no trail back to the team, feature, or workflow that generated it. Finance flags the overrun during monthly reconciliation, but engineering has no way to explain which workload caused it because no one built attribution into the infrastructure from the start.
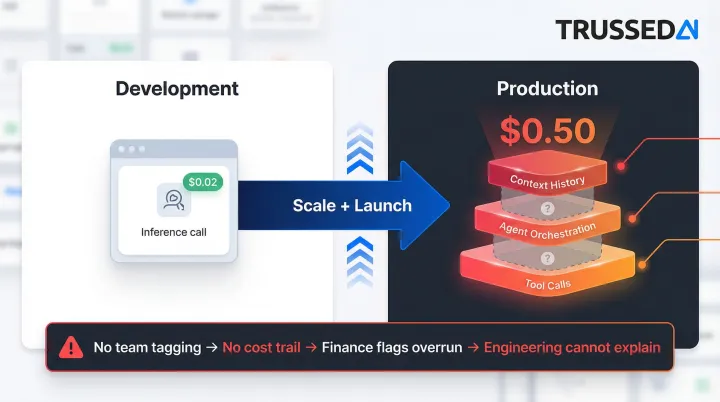
Key Cost Drivers for AI Spend
Token-Based and Usage-Based Pricing Economics
Unlike compute costs that scale with uptime, AI API costs scale with input and output complexity. Longer prompts, larger context windows, and more verbose responses each increase per-call cost in ways that are easy to overlook during development and difficult to control without per-call visibility.
Current pricing models demonstrate this variability:
| Provider | Model | Input (per 1M tokens) | Output (per 1M tokens) |
|---|---|---|---|
| OpenAI | GPT-5.4 | $2.50 | $15.00 |
| OpenAI | GPT-5.4-nano | $0.20 | $1.25 |
| Anthropic | Claude Opus 4.6 | $5.00 | $25.00 |
| Anthropic | Claude Haiku 4.5 | $1.00 | $5.00 |
| Gemini 2.5 Pro | $1.25 | $10.00 | |
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 |
A 10,000-token request using GPT-5.4 costs $0.025 for input and $0.15 for output, totaling $0.175. The same request using GPT-5.4-nano totals $0.0145. That's a 92% cost reduction for tasks where the smaller model performs adequately.
Model Selection Misalignment
When frontier models are used for tasks that lighter, cheaper models could handle equally well (simple classification, FAQ retrieval, structured extraction) organizations pay a premium that compounds at scale. This decision is rarely made with cost data in front of the engineer. The default choice becomes "use the best model available" rather than "use the minimum capable model for this task."
Attribution Failure as a Structural Cost Multiplier
Model selection problems are compounded when no one can trace where the cost came from. When multiple teams route requests through shared model endpoints with no tagging or request-level tracking, spend becomes impossible to connect to the product, feature, or customer that generated it. This makes it impossible to hold teams accountable or identify which workloads are cost-inefficient. Finance sees a $50,000 monthly bill but cannot answer which of the five teams using the endpoint generated 80% of the cost.
Agentic AI Cost Multiplication
In multi-agent and tool-calling architectures, a single user action can trigger a chain of model calls, retrieval queries, and API interactions, each billed independently. Agentic models require between 5 and 30 times more tokens per task than a standard generative AI chatbot, and tool-augmented agents require over 9 times more LLM calls than simple prompting.
Token multipliers vary significantly by architecture:
- Simple agents (1-2 tool calls): 2-3x token multiplier
- Multi-step reasoning agents: 10-30x multiplier, consuming 50,000-200,000 tokens per task
- Customer support agents: a single visible interaction may trigger five model calls, three database queries, and two API lookups behind the scenes
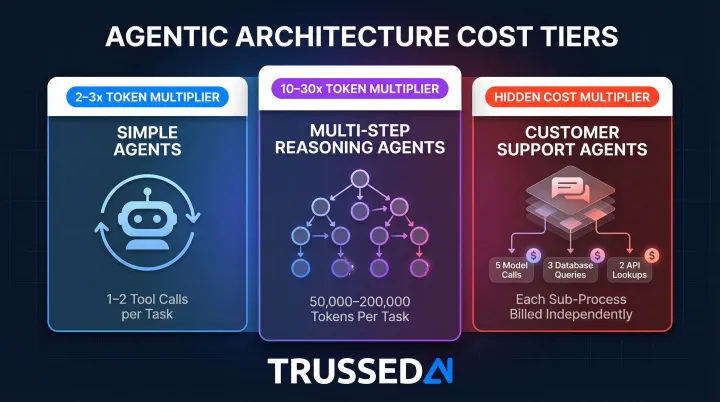
Each of those background operations is billed independently.
Absence of Governance and Enforcement Policies
Without real-time guardrails (per-team spend thresholds, model usage policies, inference cost limits), there is no mechanism to catch runaway spend before it hits the bill.
This is a context and tooling problem, not a discipline problem. Engineers cannot manage what they cannot see, and static budget spreadsheets reviewed monthly cannot catch real-time cost events like agentic loops, inference spikes, or a newly deployed model consuming 10x expected tokens.
Cost-Reduction Strategies for AI Spend
AI cost reduction requires working at three different levels: decisions made before AI runs, controls applied while it runs, and the structural environment surrounding it. Strategies targeting only one layer without addressing the others produce incomplete results.
Before AI Runs: Decisions That Drive Cost Down
These strategies reduce cost by altering choices made before or around how AI is deployed, including which models are selected, what use cases are scoped, and how prompts are engineered.
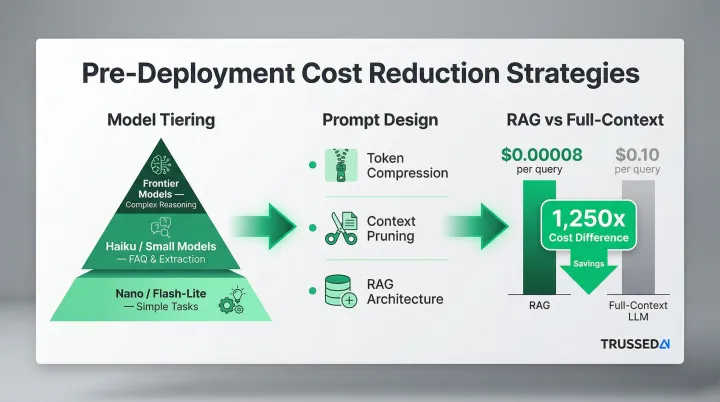
Model Tiering and Use Case Alignment
Mapping each AI use case to the minimum capable model, not the most capable available, is one of the fastest cost reduction levers. Use cases should be explicitly categorized by complexity before model selection:
- Simple classification and routing: Use nano or flash-lite models
- FAQ retrieval and structured extraction: Use haiku or small models
- Complex reasoning and content generation: Reserve frontier models like GPT-5.4 or Claude Opus
This approach delivers 90%+ cost reductions on routine tasks while maintaining quality.
Prompt Design as a Cost Discipline
Prompt length, context inclusion, and output verbosity directly drive token costs. Effective cost-reduction techniques include:
- Prompt compression: Remove unnecessary instructions and examples
- Context pruning: Include only the most relevant context rather than entire conversation histories
- RAG architecture: Retrieve only relevant context instead of processing full documents
Research from Elasticsearch Labs demonstrated that RAG systems achieved 1,250x lower cost per query than pure long-context approaches, $0.00008 per request for RAG versus $0.10 for full-context LLM queries.
Build vs. Buy and Fine-Tuning Decisions
Fine-tuning a smaller open model for a specific task can reduce inference cost significantly compared to using a general-purpose API. The TCO trade-off must include training cost, infrastructure overhead, and maintenance. The decision should be data-driven, not default.
Two profiles point in different directions:
- High-volume, stable workloads: Fine-tuning typically pays off when inference volume justifies the upfront training investment
- Diverse, evolving use cases: API flexibility outperforms, avoiding maintenance overhead as requirements shift
While AI Runs: Management Controls That Reduce Waste
These strategies reduce cost by improving control, visibility, and accountability while AI workloads are active, not by changing what runs, but by changing how well it is observed and governed.
Real-Time Cost Attribution by Team, Product, and Application
Without request-level attribution, connecting each model call to the team, product, or workflow that triggered it, there is no mechanism to identify waste, enforce budgets, or hold engineering accountable. A mature attribution model tracks cost per inference tied to business unit, not just total bill.
Trussed AI is purpose-built for this: it deploys as a drop-in proxy in front of any model endpoint, tagging every inference request with team, product, and application identifiers in real time - no code changes required across existing AI integrations. Finance teams get a live view of exactly which departments, products, and workflows drive spending, down to the token level. Engineering teams see their own cost footprint per workload and can tie model selection decisions directly to budget impact. That combination of granular attribution and zero-disruption deployment is what makes cost accountability operationally viable at scale.
Budget Controls and Anomaly Detection
Setting per-team and per-workload AI spend thresholds with automated alerts when usage deviates from baseline prevents budget overruns. Two enforcement mechanisms serve different purposes:
- Soft nudges (visibility alerts): Notify teams when spending approaches thresholds, allowing them to investigate before limits are breached
- Hard gates (policy-enforced limits): Automatically halt requests when budgets are exhausted, preventing runaway costs
Hard gates are appropriate for experimental projects and sandbox environments. Soft nudges work better for production systems where availability matters. Trussed AI enforces both mechanisms at the control plane level: budget caps are configured per team or application and enforced at inference time, so limits activate the moment a threshold is crossed rather than surfacing in a billing report days later. Anomaly detection runs continuously against each team's usage baseline, triggering alerts before a spike compounds into a serious overrun.
Governance Policies as Cost Enforcement
Static budget spreadsheets reviewed monthly cannot catch real-time cost events such as agentic loops, inference spikes, or a newly deployed model consuming 10x expected tokens. Runtime policy enforcement, rules that activate at the point of inference rather than after billing, closes this gap. Policies can automatically route requests to cheaper models, block requests exceeding token limits, or throttle usage when thresholds are approached. Trussed AI implements this as a runtime governance layer: policies are defined centrally and enforced at the proxy level across every model, agent, and workflow touching the platform. Model routing rules steer requests to the minimum capable model for each task type, reducing cost without requiring engineers to change application code. Every policy decision is logged to an audit trail, giving finance and compliance teams a complete record of what ran, when, and under which governance rule - a capability that matters as much for regulatory accountability as it does for cost control.
Around AI: Infrastructure and Workflow Design
In many cases, the surrounding infrastructure and workflow design, not the model itself, is the primary cost driver. These strategies address the system around the AI, not the AI itself.
Semantic Caching
Storing and reusing responses to repeated or semantically similar queries reduces token spend significantly on high-traffic endpoints. AWS research demonstrated that implementing Amazon ElastiCache as a semantic cache reduced LLM inference costs by up to 86% and improved average end-to-end latency by up to 88%. A VentureBeat case study documented a company reducing LLM API costs by 73% in production by using semantic caching with embedding-based similarity lookups.
Batch Processing for Non-Latency-Sensitive Workloads
Workloads such as document summarization, offline embeddings, report generation, and data classification do not require real-time inference. Batching them reduces compute cost compared to synchronous on-demand calls. Major providers offer a standard 50% discount for batch processing:
| Provider | Service | Discount | Turnaround SLA |
|---|---|---|---|
| OpenAI | Batch API | 50% | 24 hours |
| Google Cloud | Vertex AI Batch Prediction | 50% | 24 hours |
| AWS | Bedrock Batch Inference | 50% | 24 hours |
Identifying and migrating latency-insensitive workloads to batch is a fast first-pass optimization.
Commitment-Based Pricing for Predictable Baselines
Reserved capacity and committed use discounts can substantially reduce GPU and inference costs for workloads with stable, predictable volume. Organizations must align their commitment strategy with model and infrastructure flexibility:
| Provider | Commitment Vehicle | Max Discount |
|---|---|---|
| AWS | EC2 Instance Savings Plans | Up to 72% |
| AWS | SageMaker Savings Plans | Up to 64% |
| Azure | Reserved VM Instances | Up to 72% |
| Azure | Savings Plan for Compute | Up to 65% |
| Google Cloud | Resource-based CUDs | Up to 55% |
Commitments amplify savings only when usage patterns are well understood. Build attribution and observability first. Accurate forecasting is what separates a smart reservation from an expensive mistake.
What Good AI Cost Management Looks Like
Organizations that manage AI costs effectively have moved from total spend as their primary metric to unit cost, cost per inference, cost per token, or cost per customer interaction. Unit cost reveals whether efficiency is improving as volume scales, even if the overall bill is rising. A company spending $100,000 monthly on 10 million inferences ($0.01 per inference) has better unit economics than one spending $50,000 on 2 million inferences ($0.025 per inference), even though the absolute spend is lower.
The accountability shift happens when AI costs are attributed to the teams and products generating them. Engineers naturally factor cost into their design decisions when they see the impact of model selection, prompt design, and architecture choices on their team's budget. AI cost sprawl is almost always a symptom of missing attribution, not missing intent. Building attribution into the infrastructure resolves it structurally.
That attribution discipline feeds directly into the harder question: was the spend worth it? Mature AI cost management connects spend to business results, shifting the conversation from "how much did we spend on AI this month?" to one the organization has the unit economics to actually answer. The research backs this up:
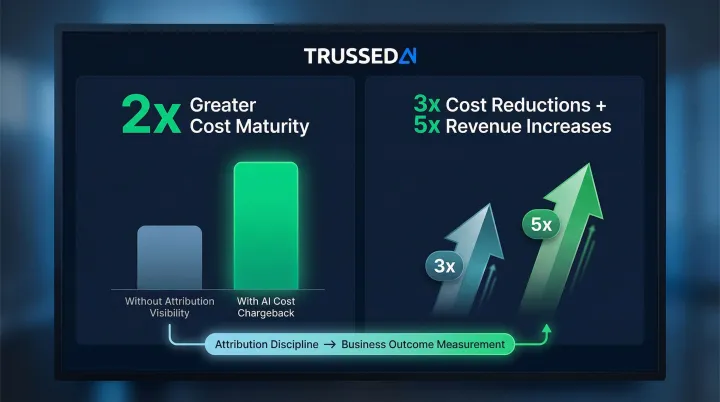
- Organizations that charge back AI costs internally show 2x greater cost maturity in attribution and cost discipline compared to those without visibility
- Companies that rigorously measure AI value achieve 3x the cost reductions and 5x the revenue increases compared to organizations with minimal AI structure
Conclusion
Sustainable AI cost reduction starts with identifying where cost actually originates: in decisions made before deployment, in missing attribution during operation, or in the structural environment surrounding the workload. Optimizing the wrong layer produces false savings, and in production systems that often means degraded latency, reduced output quality, or missed SLAs.
Effective AI cost management is continuous. Usage patterns shift, new models are introduced, agentic architectures expand, and teams add workloads faster than finance can track them. Organizations that sustain cost efficiency treat it as an operational discipline, embedded into how they route requests, attribute usage, and enforce policy at runtime, not a reactive fix after budget overruns. Trussed AI operationalizes this discipline directly: real-time token attribution per team, model routing to control which workloads reach which models, budget caps enforced at the inference layer, runtime governance policies that activate without code changes, and an audit trail generated automatically as a byproduct of every governed interaction. Cost control and governance run together through the same control plane, so neither lags the other as AI usage scales.
Frequently Asked Questions
How much does AI cost per month?
AI monthly costs vary widely, from hundreds of dollars for small API-based applications to millions for enterprises running training workloads, high-volume inference, and multi-agent systems. The more important measure is cost per unit of output (inference, token, or user interaction), not total monthly spend.
How much does enterprise AI cost?
Enterprise AI costs cover model inference, training and fine-tuning, GPU compute, vector database infrastructure, third-party API fees, and operational support. Total cost of ownership typically runs 2–4× the initial API spend once infrastructure and governance overhead are factored in.
How is AI used in cost management?
This question usually means using AI to manage costs, separate from managing AI's own costs, which is the focus of this article. AI tools can detect spending anomalies, forecast budget variance, and flag underutilized resources faster than manual review, though they still depend on accurate data and attribution to work reliably.
What are the 4 principles of cost management?
The four principles are planning (forecasting and budgeting), measurement (tracking actual spend against plan), control (enforcing limits and accountability), and optimization (reducing cost without reducing value). AI spend requires adapting each principle to token-based, usage-driven economics.
What is the 30% rule for AI?
The 30% rule holds that organizations should spend no more than 30% of their AI infrastructure budget on any single model or provider, reducing concentration risk and strengthening negotiating leverage. Actual thresholds vary by organization and workload type.


