
Introduction
The economics of production AI are fundamentally broken. Businesses routinely underestimate AI project costs by 500% to 1000% when scaling from pilot to production, and the gap isn't in model development.
For every dollar spent on AI models, enterprises typically spend far more on integration, compliance, ongoing monitoring, and infrastructure overhead. The real costs accumulate silently across tokens, API calls, agent chains, data pipelines, and the operational overhead required to make AI production-ready.
As AI moves from experimentation to production, costs compound in ways that traditional IT budgeting cannot capture. 80-85% of enterprises miss their AI infrastructure forecasts by more than 25%, and 30% of generative AI projects are abandoned after proof of concept due to escalating costs and unclear business value.
Most organizations only discover the full scope of their AI spending when the quarterly invoice arrives. At that point, the window to course-correct has already closed.
This guide examines AI consumption costs specifically through the lens of usage-based billing: the decisions that drive them up, the management practices that keep them in check, and the contextual factors that often go unaddressed until costs become unmanageable.
Key Takeaways
- AI usage-based billing charges per token, API call, or compute unit, and costs compound across every layer of the stack with each interaction
- The pilot-to-production gap is where enterprise AI budgets break down,what works at small scale looks catastrophic on a production invoice
- Agentic AI workflows multiply costs disproportionately: a single task can trigger 10 to 50 sub-calls, each billed separately
- Most AI cost overruns trace back to missing real-time visibility, attribution, and policy controls across teams and apps
- Sustainable cost management requires both upfront decision discipline and runtime controls working together
How AI Consumption Costs Build Up Under Usage-Based Billing
Unlike traditional software with a fixed per-seat fee, AI economics function like utility metering: consumption is variable, unpredictable, and charged across multiple dimensions at once. That makes the total cost of any given interaction difficult to estimate in advance.
Those dimensions compound quickly. A single user session can trigger charges across:
- Inference calls , per-token fees from the LLM provider
- Embedding generation , vector creation for retrieval pipelines
- Vector retrieval , database query costs per search
- Data transfer , egress fees between Solution
- Monitoring overhead , logging, tracing, and observability tooling
The build-up pattern follows a predictable trajectory: gradual and manageable during controlled pilots, then a sudden step-change when moving to production scale or when agentic workflows are introduced. The transition from pilot to production sees a 96% cost overrun rate, a signal that most enterprises lack the cost visibility needed to catch overruns before they compound. Costs that were invisible at low volume become structural budget pressure at scale.

That overrun problem stems directly from a visibility gap. Usage logs and metering data exist in most AI deployments , teams see API call volumes , but those signals are rarely connected to budget context in real time.
According to the FinOps Foundation's 2026 State of FinOps report, 98% of respondents now manage AI spend, yet gaining clear visibility into usage and allocating costs to specific business units remain top challenges. By the time the bill arrives, the opportunity to intervene has passed.
Key Cost Drivers for AI Under Usage-Based Billing
Model Selection and Task Mismatch
Routing routine queries to premium large language models is one of the fastest ways to inflate AI spend. The capability gap between small/mid-tier and frontier models has narrowed for standard tasks,but the pricing delta hasn't.
Consider these cost-per-token differentials:
| Provider | Model Tier | Model Name | Input Price (per 1M tokens) | Output Price (per 1M tokens) |
|---|---|---|---|---|
| OpenAI | Frontier | GPT-4o | $2.50 | $10.00 |
| OpenAI | Mid-Tier | GPT-4o-mini | $0.15 | $0.60 |
| Anthropic | Frontier | Claude Opus 4.6 | $5.00 | $25.00 |
| Anthropic | Mid-Tier | Claude Sonnet 4.6 | $3.00 | $15.00 |
| Frontier | Gemini 2.5 Pro | $1.25 | $10.00 | |
| Mid-Tier | Gemini 2.5 Flash | $0.30 | $2.50 |
According to OpenAI's model documentation, GPT-4o-mini costs 95% less than GPT-4o for input tokens. Research on simplified tool usage shows GPT-4o-mini delivers adequate accuracy for most enterprise tasks at roughly 1/16th the cost. Defaulting to frontier models for tasks that don't require them is one of the most common sources of wasted AI spend.
Agentic Workflow Multiplication
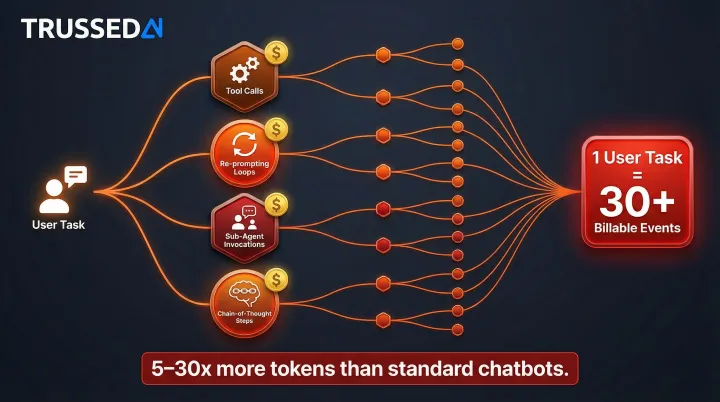
Unlike standard single-call AI features, autonomous agent systems generate a chain of API calls for each user-initiated task. Agentic models consume 5 to 30 times more tokens per task than standard chatbots as they perform many more tasks autonomously.
Multi-step workflows multiply per-interaction costs through:
- Tool calls and function invocations
- Re-prompting and reasoning loops
- Sub-agent invocations
- Chain-of-thought processing steps
Google's Vertex AI Agent Engine pricing assumes a "full session" consists of 10 runtime requests, with each runtime request generating an average of 3 session events. This means a single user-initiated task can trigger 30 billable events. Per-request cost estimates become unreliable when each interaction spawns a cascade of sub-calls.
Absence of Real-Time Attribution and Governance
When AI consumption is not tracked by team, application, or use case in real time, over-consumption goes undetected until the billing cycle closes. In large organizations running dozens of AI applications simultaneously, this compounds quickly. Teams typically have access to raw logs but lack the context to connect usage to dollars before overruns occur. That gap between metering and visibility is where budgets break down.
Data Movement and Infrastructure Overhead
For AI applications using retrieval-augmented generation or external data pipelines, embedding generation, vector search queries, and inter-service data transfer all add to inference costs. These components are billed separately and rarely appear in initial cost estimates.
These billing dimensions are often invisible until production traffic scales:
| Component | Pricing Example | Hidden Costs |
|---|---|---|
| Embeddings | $0.02 per 1M tokens (OpenAI) | Re-indexing 10M vectors costs $12–$40 |
| Vector DB Storage | $0.33/GB/month (Pinecone) | $50/month minimum on Standard plan |
| Vector Search | $16/M read units (Pinecone) | Query costs scale with dataset size |
| Data Transfer | $0.09/GB (AWS egress) | Cross-region traffic adds fees |
Vector database pricing pages often omit how costs change as datasets grow, and hidden fees like embeddings, reindexing, backups, and egress can double real production spend.

Cost-Reduction Strategies for AI Consumption Costs
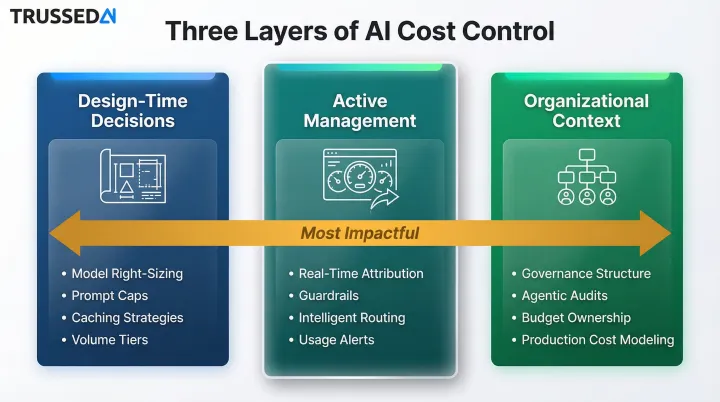
Strategies for reducing AI consumption costs vary significantly depending on where costs originate,whether from choices made at design time, practices in active management, or factors in the broader deployment environment.
Strategies That Reduce Costs by Changing Decisions
These approaches reduce cost by altering decisions made before or during the design of AI features and workflows. These choices have long-term cost implications that become expensive to reverse once systems are in production.
Right-size model selection to task complexity
Establish a policy of matching model capability to task requirements,use lightweight or mid-tier models for classification, summarization, or simple Q&A tasks, and reserve frontier models for tasks where their capability is genuinely necessary. This decision alone can reduce per-interaction costs substantially across high-volume use cases.
Define prompt and output scope limits at the application level
Set maximum input token lengths and output caps as part of feature design rather than leaving consumption unbounded. Uncapped outputs and user-submitted prompts of arbitrary length are a common source of billing surprises that are entirely preventable through design-time constraints.
Build caching into the architecture for repeated queries
Decide at design time to implement semantic or exact-match caching for common query patterns. Research indicates that 31% of enterprise LLM queries are semantically similar to previous requests. In an AWS benchmark using 63,796 real chatbot queries, enabling semantic cache reduced LLM cost by 86% and improved latency by 88%. Responses to frequently repeated inputs can be served from cache rather than triggering new inference calls.
Evaluate vendor volume tiers and committed use discounts before scaling
Research whether AI providers offer volume pricing tiers, prepaid credit packages, or committed use agreements that reduce per-unit cost at scale. OpenAI's Batch API offers 50% cost discount for asynchronous workloads. Azure OpenAI Provisioned Throughput Units provide substantial term discounts via one-month or one-year reservations. Model what usage thresholds would make those commitments financially rational before committing.
Design-time decisions set the cost ceiling. The next layer of control determines whether teams can stay beneath it once systems are live.
Strategies That Reduce Costs by Changing How AI Is Managed
These approaches reduce cost by improving control, visibility, and consistency while AI systems are actively running. These are management-layer interventions that determine whether teams can detect and respond to cost signals before they become overruns.
Implement real-time cost attribution across teams, models, and applications
Establish visibility that shows who is consuming what, on which model, and through which application,in real time rather than in retrospect. This is the foundational capability that enables all other cost controls.
Without this attribution layer, budget owners are working blind. Purpose-built AI control planes can provide this visibility without requiring custom instrumentation across every application.
Enforce spending guardrails at the policy level
Apply budget ceilings and consumption limits at the policy layer,not just at the infrastructure level,so individual applications, agents, or teams cannot exceed defined thresholds without triggering an automated control response. Teams stop discovering overruns after the fact and start preventing them before they occur.
Use intelligent routing to direct queries to the most cost-appropriate model
Implement dynamic routing logic that sends simple requests to lower-cost models and escalates complex requests to more capable models based on query characteristics. Two independent studies quantify the impact:
- The RouteLLM framework demonstrated routing can reduce costs by over 2x without substantially compromising response quality
- Hybrid inference allows up to 40% fewer calls to large models with no drop in response quality
Configure proactive usage alerts at defined consumption thresholds
Set alerts that notify responsible owners when consumption reaches 60%, 80%, and 100% of a defined budget. This gives teams time to investigate and respond before overruns occur rather than discovering them in the billing summary.
Management controls keep live systems within bounds. The third category addresses something harder to measure: the organizational context that either amplifies or dampens cost growth over time.
Strategies That Reduce Costs by Changing the Context Around AI
These approaches reduce cost by addressing the organizational, structural, and workflow factors surrounding AI deployments. In many cases, the context in which AI operates is the real driver of cost growth, not the AI system itself.
Establish governance structures at design time, not after deployment
Most AI cost surprises occur because teams add budget ownership, usage policies, and attribution retroactively,after costs have already escalated. Teams that establish clear cost ownership, acceptable use policies, and attribution models before production deployment have significantly more control over their spending trajectory.
Audit agentic workflow chains for redundant or unnecessary API calls before deployment
Multi-step agent workflows deserve explicit review for over-calling patterns,tool invocations that could be batched, redundant verification steps, or recursive loops that can trigger without bounds. Catching these in design review is far less expensive than discovering them on a production invoice.
Assign AI consumption budget ownership at the team or application level
When teams are accountable for their own AI spend,rather than consuming from a shared, undifferentiated pool,usage patterns change. Ownership creates the organizational incentive to optimize that centralized controls alone cannot.
Apply production-scale cost modeling before moving from pilot to production
Before promoting any AI feature or workflow to production, model its cost behavior at 10x, 50x, and 100x the pilot usage level. Most production cost surprises are predictable at this stage but are skipped in the pressure to deploy quickly.
Conclusion
AI consumption costs under usage-based billing are not inherently unmanageable,they reflect the cumulative effect of decisions made at design time, the quality of controls applied during active use, and the organizational context surrounding the deployment. Identifying where costs originate is more valuable than cutting spend across the board.
Effective cost management for AI is continuous rather than one-time. As models evolve, usage scales, and agentic workflows proliferate, the governance layer must evolve in parallel. Organizations that treat cost control as an operational discipline rather than a remediation exercise will maintain control as their AI deployments grow.
The gap between pilot economics and production costs is where most enterprise AI budgets break down. It is also where disciplined governance, real-time visibility, and proactive policy enforcement deliver the greatest return.
Frequently Asked Questions
What is usage-based billing for AI, and how does it differ from traditional SaaS pricing?
Usage-based billing charges per unit of consumption,tokens, API calls, or compute time,rather than a fixed subscription fee. Costs become variable and harder to forecast compared to traditional SaaS models, where monthly expenses stay predictable regardless of how intensively teams actually use the system.
Why do AI costs spike unexpectedly even when user traffic stays relatively flat?
AI costs can increase independent of user traffic when agentic workflows generate multiple API calls per task, when prompt lengths grow, or when background processes like embedding generation and data pipeline jobs run without consumption limits. Refreshing embeddings or re-indexing vector databases can double write costs overnight.
How can enterprises set spending limits on AI consumption without disrupting active workflows?
Policy-level guardrails,distinct from infrastructure-level rate limits,can enforce budget ceilings at the application or team level while allowing normal operations to continue within defined thresholds. Alerts trigger before hard stops, giving teams time to respond without service interruption.
What hidden costs are most commonly overlooked in AI usage-based billing?
Beyond direct model inference, enterprises routinely miss embedding generation, vector search calls, data transfer fees, and compliance monitoring overhead. Re-indexing costs and cloud egress fees alone can add 50–100% to initial projections.
How does agentic AI change the cost management challenge compared to standard AI features?
Agentic systems generate chains of API calls per user task rather than a single call, multiplying billable events in hard-to-predict ways. Per-interaction costs run 5 to 30 times higher than standard chatbots, which means per-request estimation is no longer enough , workflow-level cost modeling becomes necessary.
What is the first step enterprises should take to get AI consumption costs under control?
Real-time attribution,understanding which teams and models are driving spend as it happens,is the prerequisite for all other cost controls. Organizations without this visibility cannot act on cost signals before they become overruns.


