
Introduction
Enterprise AI budgets are growing fast, but most organizations still can't answer a basic question: which model, team, workflow, or agent is actually driving their spend. Gartner forecasts worldwide generative AI spending will reach $644 billion in 2025 - a 76.4% increase from 2024. Yet 84% of companies report more than a 6% hit to gross margins from AI costs, with 26% reporting erosion of 16% or more.
Without cost visibility, engineers spend hours on reactive forensics, FinOps teams can't plan effectively, and optimization stays speculative. The waste is real and measurable.
In regulated industries, the stakes are higher still. Cost accountability isn't just operational , it's a compliance requirement. The EU AI Act legally mandates automatic event logging with a minimum 6-month retention period for high-risk systems, while the NIST AI RMF requires strict provenance and telemetry.
This guide explains what AI cost observability is, why it breaks down at scale, and how to build the attribution and visibility your organization needs.
Key Takeaways
- AI cost observability provides real-time, granular visibility into token and dollar consumption,not just monthly provider invoices
- Biggest cost leaks are invisible: context window bloat, retry cascades, agentic tool overhead, caching misses, and shadow API usage
- Effective observability rests on five pillars , instrumentation, attribution, correlation, forecasting, and governance , each targeting a different layer of AI spend
- For regulated enterprises, cost observability serves double duty: FinOps efficiency and audit accountability
- Trussed AI's control plane captures cost telemetry automatically as a byproduct of governed AI interactions
What Is AI Cost Observability?
AI cost observability goes beyond billing dashboards to provide a real-time, per-request view of token consumption mapped to models, teams, workflows, and business outcomes. It answers three questions:
- Where is spend coming from?
- Why is it happening?
- Is it justified by the output?
Traditional cloud cost monitoring and FinOps tools fall short for AI workloads because they surface totals, not causes. A monthly report showing $50,000 in LLM spend tells you nothing about which prompt version, agent step, or workspace is responsible.
FinOps was built for deterministic infrastructure like VMs and storage, tracking hourly instance costs. AI workloads require a different approach , token usage and API calls run through abstracted meters that have no direct tie to hardware.
AI cost observability also differs from general LLM monitoring in one key way: monitoring tracks uptime and latency, while observability connects operational signals , tokens, retries, routing decisions , to financial outcomes. That shift enables proactive management rather than reactive cleanup.
Gartner defines LLM observability as solutions that monitor, analyze, and provide actionable insights into LLM behavior and performance, going beyond standard IT measurements to cover hallucinations, bias, and token utilization.
That traceability matters most in regulated industries. When every AI interaction is traced to a team, model, and business purpose, cost attribution satisfies FinOps accountability requirements and generates the audit evidence regulators need - turning cost telemetry into governance evidence.
Where AI Costs Actually Leak
Context Window Bloat
The single greatest hidden cost in most production AI applications is context window creep. Because most LLM APIs are stateless, applications must resend the entire conversation history with every new message - so teams routinely concatenate full conversation histories, system prompts, and retrieved documents without trimming or summarizing, causing input token counts to balloon.
The compounding effect is massive. Even a few hundred extra tokens per request repeated across millions of calls creates enormous monthly overage. While output tokens are priced higher (typically $10-$15 per million tokens vs. $2.50-$3.00 for input), the compounding volume of input tokens in conversational applications almost always dominates total spend.
Retry and Failover Cascades
Default SDK settings and provider billing semantics create hidden cost multipliers. Both the OpenAI and Anthropic Python SDKs automatically retry certain errors,like 429 Rate Limit or >=500 Internal errors,2 times by default with exponential backoff. If an application adds its own retry logic on top of the SDK, a single transient failure can result in up to 12 HTTP requests, silently multiplying costs.
One misconfigured retry policy can multiply cost per request by 3-5x before anyone notices. Aggressive failover strategies compound this by silently routing failed calls to more expensive fallback models. Providers also typically charge for compute used, so if a model performs a task but the connection drops or times out, the provider still charges for the tokens processed.
Agentic Tool Call Overhead
In multi-step agent workflows, every tool call,web search, database query, vector retrieval,carries both token costs and external API fees. Agents that replan frequently or call tools redundantly can generate costs that dwarf the core model spend.
LangChain benchmarks reveal the magnitude of this overhead:
- Subagents pattern: 5 model calls, ~9,000 tokens
- Router pattern: 5 model calls, ~9,000 tokens
- Handoffs pattern: 7+ model calls, ~14,000+ tokens
Complex multi-domain tasks using sequential "Handoff" patterns generate 40% more model calls and nearly 60% more token overhead compared to isolated subagents. An autonomous agent behaves like a chatty analyst, triggering multiple planning steps, memory lookups, and retrieval queries for a single customer issue.

Caching Misses and Misconfiguration
Semantic caching can eliminate 30–90% of repeat query costs,but only if it's properly configured. Semantic caching stores responses based on the semantic meaning of queries using vector embeddings, allowing applications to bypass the LLM for similar requests.
AWS benchmarks using Amazon ElastiCache as a semantic cache on 63,796 real user chatbot queries reduced LLM inference costs by up to 86% and improved average latency by 88% at a 0.75 similarity threshold, maintaining 91.2% accuracy. Academic research demonstrates that semantic caching can reduce API calls by up to 68.8%.
Teams that disable caching for specific workflows, use overly narrow similarity thresholds, or set TTLs too short forfeit this savings entirely. Given the 86% cost reduction possible at a well-tuned threshold, a misconfigured cache isn't a minor oversight,it's a budget leak hiding in plain sight.
Shadow Usage and Unattributed Spend
Shared API keys reused across teams create usage spikes with no clear owner. Shadow AI,the unauthorized use of cloud AI tools by employees,is a critical security and cost concern for 74% of enterprises. Forrester notes that 51% of public-sector employees use an AI tool daily, often bypassing traditional procurement through low-cost micro-transactions.
Without attribution, organizations can't determine which product, team, or agent triggered an invoice spike,making it impossible to optimize or hold anyone accountable.
The Core Pillars of AI Cost Observability
Effective AI cost observability rests on five foundational capabilities that must work together. Visibility alone is insufficient; the system needs to connect signals to owners, outcomes, and controls.
Instrumentation
Instrumentation is the data capture layer. Every LLM request must log token counts (input and output), model and provider metadata, latency, retry events, routing decisions, and guardrail outcomes,all tied to a unique trace ID.
Without this telemetry, cost remains a provider-side number with no actionable context. Capture must happen at the request level, not just aggregate totals:
- Input and output token counts per request
- Model and provider identifiers
- Request latency and completion time
- Retry attempts and failure modes
- Routing decisions and fallback triggers
- Guardrail evaluations and policy outcomes
Attribution
Without attribution, there's no accountability. Captured cost data must be mapped to the right owners,workspace, team, model, project, user, agent, or tool. This prevents shadow usage, supports showback and chargeback models, and creates the organizational accountability necessary for responsible AI scaling.
Without attribution, cost optimization becomes impossible because you can't identify who or what is responsible for spending patterns. Attribution enables organizations to move from aggregate cloud budgets to precise, use-case-driven unit economics.
Correlation
Correlation is the value layer , it's what separates optimization from blind cost-cutting. Connecting spend to quality, latency, safety pass rate, or grounding accuracy lets teams evaluate whether higher cost actually produces better outcomes.
Correlation enables teams to make informed decisions about model selection, prompt engineering, and workflow design. If a high-cost reasoning step correlates with better outcomes, preserve it. If it doesn't, cap iterations or route to a smaller model.
Forecasting
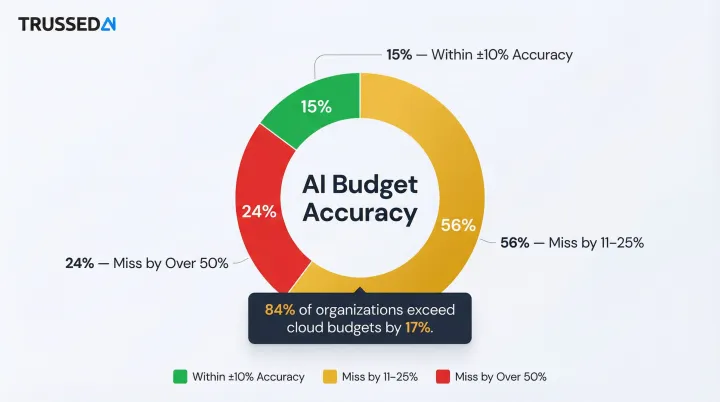
Forecasting is the planning layer. Historical cost telemetry enables teams to predict future spend, set realistic budgets, and catch anomalies before invoices arrive. According to Flexera's 2025 State of the Cloud report, 84% of respondents cite managing cloud spend as their top challenge , and cloud budgets are already exceeding limits by 17%.
AI costs are especially hard to predict. The numbers tell the story:
- Only 15% of companies forecast AI costs within ±10% accuracy
- 56% miss by 11–25%
- 24% miss by more than 50%
That unpredictability stems from fragmented tooling, untracked consumption, and the non-deterministic nature of agentic workflows.
Governance
Governance closes the loop. Budget limits, per-workspace caps, anomaly alerts, and routing rules enforce spend policies in real time , turning cost observability from a reporting tool into an operational safety net. For enterprises in regulated industries, this matters beyond finance: runaway AI spend can trigger compliance exposure just as readily as a policy violation.
Governance mechanisms include:
- Budget thresholds with alerts and hard stops
- Per-workspace and per-team spending limits
- Anomaly detection for unexpected cost spikes
- Routing policies that optimize for cost vs. quality
- Real-time enforcement at the execution layer
AI Cost Observability in Practice: A Practical Walkthrough
This walkthrough uses a realistic enterprise scenario: a multi-agent customer support workflow with several models, tool integrations, and multiple teams consuming a shared AI platform.
Step 1 – Define the Cost Objective
Establish what success looks like before instrumenting. The goal is to understand cost per successful customer resolution, not just total token spend. Vague goals like "spend less" lead to blind cuts that damage quality , tying cost to a business outcome creates targets you can actually act on.
Step 2 – Instrument and Attribute the Stack
Route all LLM calls through a centralized gateway that tags each request with agent identity, workflow step, team, and model. The common mistake here is instrumenting the model call but missing the tool calls and retry events,leaving the most expensive behaviors invisible.
Ensure your instrumentation captures:
- Every model invocation with full metadata
- Tool calls including external API costs
- Retry attempts and failover events
- Context window size per request
- Cache hits and misses
Step 3 – Surface and Analyze Cost Patterns
Use attribution data to rank cost by team, agent step, and model. This often surfaces patterns that aren't obvious from total spend alone: one agent step consuming 60% of tokens, a planning loop running 8 iterations when 3 suffice, a retrieval tool called redundantly on every request.
The common error at this stage is optimizing the most visible cost, not the highest one. Focus on the workflows and agent steps that drive the majority of spending, not the ones that are easiest to instrument.
Step 4 – Correlate Cost with Outcomes and Act
Cross-reference expensive agent steps against resolution success rates. The logic is straightforward: if a high-cost reasoning step correlates with better outcomes, preserve it. If it doesn't, cap iterations or route to a smaller model.
Once you've identified where to cut, act on it:
- Implement semantic caching for repeated query patterns
- Test similarity thresholds to maximize cache hit rates without sacrificing accuracy
- Set budget alerts per workspace before costs drift
Step 5 – Govern and Iterate
Set ongoing budget thresholds, anomaly alerts, and per-workspace limits. Establish a feedback cadence to keep governance current:
- Daily: anomaly checks on spend spikes
- Weekly: cost trace reviews by team and workflow
- Monthly: baseline snapshots to track drift over time
Cost observability is an operational discipline, not a one-time audit. The patterns that drive cost today will shift as your AI systems grow , governance that isn't actively maintained becomes a gap.
How Trussed AI Can Help
Trussed AI is an enterprise AI control plane where cost observability emerges as a byproduct of governance. Its drop-in proxy integration requires zero changes to application code, so every governed interaction automatically captures the telemetry needed for cost attribution:
- Token counts and model metadata
- Routing decisions and retry events
- Per-request cost attribution by team, application, and workflow
Organizations get full visibility into spend across teams, models, applications, and agentic workflows. For regulated industries like insurance, healthcare, and financial Solution, this attribution data also serves as audit-ready governance evidence,satisfying both FinOps and compliance requirements in a single system.
Trussed AI enforces budget limits, routing policies, and anomaly guardrails at runtime , before costs spiral, not after the invoice arrives. Audit trails are maintained automatically. Finance teams get real-time visibility into exactly where AI spend is going by business unit, project, and provider, with enough granularity to evaluate ROI at the use-case level.
Frequently Asked Questions
What is the difference between AI cost observability and traditional cloud cost management?
Traditional cloud cost management tracks infrastructure resource spend at the billing level,VMs, storage, databases. AI cost observability drills into per-request, per-model, and per-agent telemetry to reveal the operational behaviors driving LLM spend, making optimization possible at the code and workflow level, not just the budget level.
What are the biggest hidden cost drivers in LLM and agentic AI systems?
The top culprits are context window bloat from resending full conversation histories, retry and failover cascades that multiply requests 3-5x, redundant tool calls in agentic workflows, caching misses from misconfiguration, and unattributed shadow usage from shared API keys. None of these show up in standard billing reports.
How do you attribute AI costs to specific teams, projects, or workflows?
Route all LLM calls through a centralized gateway that captures workspace, team, model, agent, and project metadata on every request. That metadata ties directly to financial outcomes, giving teams and project owners clear visibility into what they're spending and why.
What metrics should enterprises prioritize to understand and manage their AI spend?
Focus on cost per request by model and workflow, cost per successful outcome, cache hit rate, budget burn rate by team, retry rates, and anomaly alerts for unexpected cost spikes. These metrics reveal both efficiency and value, enabling informed optimization decisions.
How does AI cost observability support compliance requirements in regulated industries?
Every traced interaction,tagged with team, model, and business purpose,creates an audit trail connecting spend to approved use cases and governance policies. That trail serves as compliance evidence for mandates like the EU AI Act's logging requirements, turning operational telemetry into regulatory documentation.


