
AI API pricing is consumption-based with no natural ceiling, meaning costs can change overnight without any visible trigger. Unlike traditional infrastructure with reserved capacity and predictable per-request pricing, AI APIs charge per token consumed, and token consumption can multiply silently through agent loops, context bloat, and routing inefficiencies. 84% of enterprises report AI infrastructure costs eroding gross margins by more than 6%, and 80% miss their AI forecasts by over 25%.
This post breaks down the five root causes driving most AI API cost explosions and the practical prevention strategies that return control to your team before the bill arrives.
Key Takeaways
- AI APIs charge per token, not per request, making costs 10-100x more unpredictable than traditional infrastructure
- Agentic systems consume 5-30x more tokens than single-turn interactions due to planning loops, tool calls, and retries
- Five structural gaps drive overruns: token-based pricing blind spots, agent loops, context bloat, missing model routing, and multi-provider sprawl
- Preventing overruns requires token-level monitoring, hard spend limits, intelligent model routing, semantic caching, and context management
- Cost governance belongs in AI operations permanently. Treat it as a FinOps discipline, not a one-time audit
Common Causes of AI API Cost Explosions
Unlike cloud infrastructure, AI APIs have no reserved capacity or natural spending ceiling. Costs scale directly with usage, and usage can change overnight without any visible trigger. A new feature ships, an agent encounters an edge case and retries indefinitely, or a prompt grows from 500 tokens to 50,000 tokens as context accumulates.
Cost explosions rarely stem from a single mistake. They typically arise from one or more structural gaps in how AI systems are designed, monitored, or governed.
Cause 1: Invisible Token-Based Pricing
Token-based pricing replaces the fixed, predictable per-request model of traditional APIs. Instead of paying $0.01 per API call regardless of payload size, you pay based on how many tokens the model processes, both input and output. Token costs vary dramatically by model tier, and premium models can cost 12.5x more than budget alternatives. A single long-context request can cost as much as dozens of simple ones.
Cost differential by model tier (per 1M tokens):
| Provider | Budget Model | Premium Model | Budget Input/Output | Premium Input/Output |
|---|---|---|---|---|
| OpenAI | GPT-5.4 nano | GPT-5.4 | $0.20 / $1.25 | $2.50 / $15.00 |
| Anthropic | Claude Haiku 4.5 | Claude Opus 4.6 | $1.00 / $5.00 | $5.00 / $25.00 |
| Gemini 2.5 Flash-Lite | Gemini 2.5 Pro | $0.05 / $0.20 | $1.25 / $10.00 |

Without token-level tracking during development, teams have no feedback loop. They discover the cost model is broken only when the bill arrives. Developers optimize for functionality, not token efficiency, because they lack visibility into how design decisions translate to spend.
Cause 2: Agent Loops, Retries, and Runaway Requests
Agentic AI systems don't just call the LLM once. A single user request can trigger planning calls, parameter generation, tool execution, evaluation, and correction loops, each burning tokens. Agentic workflows consume 5 to 30 times more tokens per task than standard chat interactions. Complex multi-agent systems can consume 200,000 to over 1 million tokens per task.
The retry loop failure mode is catastrophic: a bug causes an agent to call the same endpoint repeatedly, and because everything technically "works," the loop runs undetected for hours. One documented incident involved two LangChain agents locked in a recursive loop for 11 days, burning $47,000. Another case involved a stolen API key generating 14,200+ failed requests in 48 hours, costing $82,314.
Cause 3: Context Bloat
As an agent progresses through a task, it often appends all prior steps and API responses to every new prompt. This compounds token usage exponentially. A task that started with a 500-token prompt can balloon to 50,000 tokens by the final step.
Because LLM APIs are stateless, conversation history must be repeated every time. By turn 10 of a conversation, the cost per call is approximately 7x the cost of turn 1. Google Vertex AI explicitly charges per turn for all tokens present in the session context window, meaning tokens from past turns are re-processed and billed again in each new turn.
RAG pipelines amplify the problem further. Large document chunks get injected into every call regardless of relevance. Traditional RAG sends roughly 4,000 tokens per query; long-context approaches that dump full corpus data can send 200,000+ tokens per query.
Cause 4: Model Drift and No Routing Strategy
Model drift occurs when a team upgrades to a more capable model in pursuit of higher output quality without connecting that decision to budget impact. OpenAI's GPT-5.4 is 12.5x more expensive for inputs than GPT-5.4 nano, and Anthropic's Claude Opus 4.6 is 5x more expensive than Claude Haiku 4.5.
The cost impact compounds when there's no routing strategy. Premium models end up handling routine tasks that a cheaper model could handle equally well:
- Classification and intent detection
- FAQ lookup and simple summarization
- Form validation and structured extraction
Research shows 68% of enterprise queries do not require premium models, yet most organizations default all traffic to the most expensive tier.

Cause 5: Multi-Provider Sprawl and Shadow Usage
Organizations accumulate AI spend across multiple providers, including OpenAI, Anthropic, AWS Bedrock, and Vertex AI, and internal tools, each with different billing cycles and units. 37% of enterprises now use 5 or more AI models in production, making it nearly impossible to see total AI spend in one place.
Shadow usage compounds the problem when teams share a single API key or lack per-team attribution, so one team's overrun hides inside the aggregate bill. The scale of this blind spot is striking:
- 71% of IT leaders admit little to no control over where AI costs originate
- Half of companies with AI-core products don't track LLM API costs at all
Each of these causes is preventable, but only with real-time visibility and enforcement built into the AI stack from the start.
What Happens When AI API Cost Overruns Go Unchecked
Budget overruns surface only at month-end billing, triggering emergency cost forensics that pull engineering time away from product work. Leadership loses confidence in AI initiatives when forecasts miss by 25-50%.
In regulated industries, the damage compounds. Ungoverned models and prompts accumulating without audit trails create direct compliance exposure, and that exposure carries its own financial risk.
77% of surveyed executives reported financial losses from AI-related incidents, with an average hit of $800K over two years. Gartner predicts that at least 30% of generative AI projects will be abandoned after proof of concept by the end of 2025 due to poor data quality and inadequate risk controls, including cost overruns.
Warning Signs You're About to Hit an Overrun
Watch for these patterns before the invoice arrives:
- Spend rising without traffic growth: Token consumption climbing 40% week-over-week while user activity stays flat signals runaway loops or context bloat multiplying costs invisibly.
- No baseline before launch: Deploying a new feature or agent without a cost estimate means you have no reference point to detect anomalies. Cost spikes go unnoticed until they're already significant.
- No unified spend view: When AI costs span multiple providers with no single dashboard, overruns stay hidden until invoices arrive from separate vendors weeks apart.
How to Prevent AI API Cost Overruns
Prevention requires layered controls: visibility first, then limits, then routing efficiency, then caching. Each layer targets a different failure mode.
Prevention Measure 1: Establish Real-Time Token-Level Monitoring and Attribution
Instrument every AI call to capture tokens consumed, model used, the team or feature that triggered the call, and estimated cost, tracked per workflow, per agent, and per team, not just in aggregate. Attribution should span:
- Teams and business units
- Models and providers
- Applications and workflows
- Projects and cost centers
Without this granularity, a retry loop or context bloat problem stays invisible until month-end, by which point the damage is done. Daily visibility with anomaly alerts ("today's spend is 40% above baseline") gives teams time to investigate before costs compound.
Trussed AI's control plane provides real-time cost tracking and attribution across teams, models, and applications as a built-in capability, operating as a drop-in proxy that requires no changes to application code.
Implement this before any AI feature ships to production. For existing deployments, audit and instrument them as an early fix. Don't wait for the next billing cycle to reveal a problem.
Prevention Measure 2: Set Hard and Soft Spend Limits with Automated Enforcement
Define explicit monthly budgets at the workspace, team, and task level. Configure three enforcement tiers:
- Soft limit alert at 75% of budget that notifies the responsible team lead
- Hard limit that halts or downgrades the agent when the ceiling is hit
- Human-approval step before the agent can exceed its budget for high-value workflows
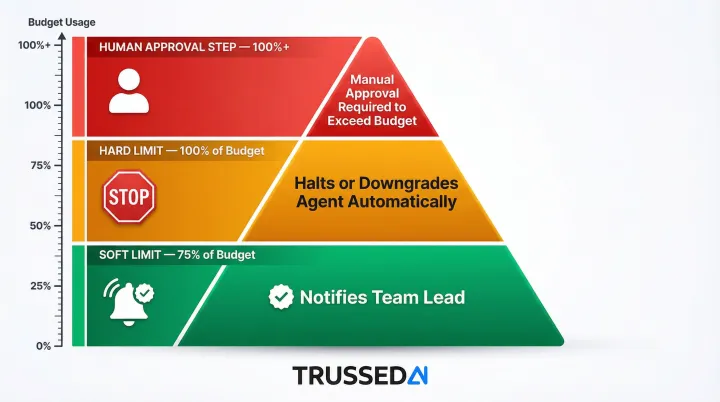
Static budgets alone don't prevent overruns. Automated enforcement does. A runaway loop stopped at 100% of budget causes a fraction of the damage it would cause running overnight unchecked.
Set limits at project initialization and review them quarterly as usage patterns shift.
Prevention Measure 3: Deploy Intelligent Model Routing
Classify incoming requests by complexity and route them to the least expensive model that can deliver acceptable quality. Smaller, cheaper models handle high-volume, routine tasks well:
- Summarization
- Classification
- Simple Q&A
- FAQ lookup
Reserve premium models for complex reasoning or high-stakes outputs.
Model selection is often the single largest cost lever available. Intelligent routing can reduce API spend by 41% to 85%, with 68% of traffic handled by models costing 1/30th of the premium tier. RouteLLM achieved reductions over 85% on standard datasets while maintaining 95% of premium model performance.
Design routing logic into agent architecture from the start. Retrofitting it into production systems later is significantly harder.
Prevention Measure 4: Use Caching and Context Management
Two techniques work together here. Semantic caching reuses LLM responses for similar queries, not just exact matches, eliminating redundant inference costs. Context window management keeps token counts from snowballing: summarize prior steps rather than appending full responses, and for RAG workflows, cache retrieval results per query to avoid redundant vector searches.
Semantic caching can reduce LLM API costs by 73% to 86%, lifting cache hit rates from 18% to 67% and cutting latency by 65–88%. Context pruning handles the other half of the equation, stopping the exponential token growth that drives context bloat.

Major providers offer native prompt caching discounts:
- Anthropic: Cache read tokens cost 0.1x the base input price (90% discount)
- OpenAI: Prompt caching reduces input costs by up to 90% automatically for prompts over 1,024 tokens
- Google: Implicit caching provides 90% discount on cached tokens for Gemini models
Design caching in during prompt engineering, as it's difficult to add cleanly after the fact. Enforce context management as a coding standard for any agent that maintains multi-step state.
Tips for Long-Term Cost Control and Governance
Sustaining cost control requires treating AI spend the same way mature engineering teams treat infrastructure: as an ongoing operational discipline, not a one-time setup task.
- Establish weekly cost review cadences where engineering teams review token spend dashboards weekly and leadership reviews monthly with ROI framing (cost per outcome, not just total spend)
- Conduct regular agent behavior audits to identify which agents are generating retry loops, which prompts have grown in token length, and which models are handling tasks they're overqualified for
- Embed cost governance into your AI deployment workflow so cost estimates and token baselines are required before any new AI feature or agent is promoted to production, not reviewed after the fact
- Review token budgets, model routing rules, and caching configurations quarterly, as usage patterns shift, and governance configurations that made sense at launch often don't reflect how agents actually behave six months in
The harder challenge at scale is enforcement. Individual teams following best practices inconsistently is how governance breaks down, and manual oversight doesn't scale across dozens of AI applications.
For enterprises operating across multiple teams and regulated use cases, a runtime control plane like Trussed AI's addresses this directly: cost policies, model routing rules, and compliance guardrails are enforced automatically at the infrastructure layer, not left to individual teams to remember. According to Trussed AI, customers typically see a 50% reduction in manual governance workload and are live with operational workflows within four weeks.
Conclusion
AI API cost overruns are not a planning failure. They are the predictable outcome of usage-based pricing without visibility or structural controls. The organizations that prevent overruns are the ones with enough visibility to act before costs compound.
Monitoring, hard limits, and intelligent routing return control to the team before the bill arrives. Sustainable AI operations come down to one capability: knowing where spend is going in real time and having the mechanisms to stop it when it drifts.
Frequently Asked Questions
Why do AI API costs spike so suddenly and without warning?
AI APIs charge per token consumed rather than per request, so costs scale directly with usage complexity and volume. A single buggy deployment or runaway agent loop can generate thousands of dollars in API calls within hours before any alert fires.
What makes token-based pricing harder to manage than traditional API pricing?
Traditional APIs charge a fixed rate per request, making costs predictable. Token-based pricing varies by prompt length, response length, model, and context size , the same feature can cost 10 to 100 times more depending on model tier and context window alone.
How do AI agent reasoning loops cause runaway costs?
Agentic AI systems call the LLM multiple times to plan, act, evaluate, and correct. If an agent encounters an error or unexpected response, it may retry in a loop, burning tokens on every iteration without producing useful output. Detection can take days when no circuit-breaker or spend alert is in place.
What is the difference between a soft limit and a hard limit for AI API spend?
A soft limit triggers an alert to the responsible team when spend reaches a set threshold (e.g., 75% of budget), while a hard limit automatically halts or downgrades the agent when the ceiling is hit, preventing further spend without requiring manual intervention.
How should enterprises track AI API costs across multiple teams and models?
Effective tracking requires three things:
- Per-team and per-workflow attribution, not just aggregate billing data
- A unified dashboard spanning multiple providers and models
- Daily anomaly alerts so overruns surface in hours, not at month-end
What is the first step to getting AI API costs under control?
The first step is visibility: instrument every AI call to capture token usage, model, and cost attribution per team and workflow. You cannot set meaningful limits or optimize routing until you know where current spend is actually coming from.


