
Introduction
Enterprise GenAI spending is surging, but most organizations lack the visibility to predict or control it. 96% of organizations deploying GenAI report costs higher than expected, with 71% admitting they have little to no control over where those costs originate. That's not statistical noise: 80-85% of enterprises miss AI forecasts by 25% or more.
The pattern plays out the same way across organizations: teams discover overspend after the fact, finance escalations happen at quarter-end rather than when thresholds are crossed, and GenAI initiatives get cancelled not for lack of value but for lack of financial control.
At least 30% of GenAI projects will be abandoned after proof of concept by the end of 2025, with escalating costs cited as a primary driver.
GenAI API costs are controllable. They become expensive because of decisions made without visibility, across tokens, teams, workflows, and governance gaps. Trussed AI's runtime control plane is purpose-built to close those gaps, giving enterprises real-time attribution, enforcement, and visibility from the moment a request is issued. This article breaks down where those costs actually originate and how Trussed AI helps address each one.
Key Takeaways
- Context window growth, agentic call chains, idle reserved capacity, and shadow usage compound costs well beyond headline token rates
- Model selection mismatches, prompt inefficiency, and missing cost attribution quietly amplify your base spend
- Cost control starts with visibility. Most default API integrations surface almost no useful cost metadata, which is exactly the gap Trussed AI is designed to fill
- Strategies fall into three categories: decisions made before deployment, controls applied during active use through Trussed AI, and changes to the surrounding system context
- Governance infrastructure like Trussed AI separates organizations with predictable API spend from those with quarterly surprises
How GenAI API Costs Typically Build Up
API costs don't arrive as a single visible line item. They accumulate across multiple compounding layers. Each API call may be cheap in isolation, but volume, context size, chained requests, and idle reservations transform the total into something unrecognizable from the original estimate.
The build-up starts gradually during pilots, then accelerates sharply at scale. Early usage looks manageable. Teams are calling single endpoints with small prompts. Once more teams onboard, the picture changes fast:
- Context windows expand as workflows grow more complex
- Agents begin chaining multiple API calls per task
- Parallel workloads stack token consumption across users and systems
- Idle reservations and redundant retries add background spend
Costs multiply non-linearly. What looked like a $500/month pilot can become a $15,000/month production bill with no obvious single cause.
These costs stay invisible until scale or stress exposes them. Without per-request attribution, teams can't trace which applications, agents, or users are driving consumption. The bill arrives with no breakdown of what caused it. Trussed AI eliminates this blind spot by tagging every request with team, application, and model metadata in real time, so the cost picture is clear before the invoice arrives.
Key Cost Drivers for GenAI APIs
Token Pricing Asymmetry and Output Token Dominance
Input and output tokens are not priced equally. Output tokens consistently cost 4x to 5x more than input tokens across major providers:
| Provider | Model | Input (per 1M tokens) | Output (per 1M tokens) | Ratio |
|---|---|---|---|---|
| OpenAI | GPT-4o | $2.50 | $10.00 | 4x |
| Anthropic | Claude 3.5 Sonnet | $3.00 | $15.00 | 5x |
| Gemini 2.0 Flash | $0.15 | $0.60 | 4x |

Most teams design prompts without accounting for this asymmetry. Applications that generate long outputs, multi-turn responses, or verbose structured data carry significantly higher costs. The output premium directly punishes any workflow that prioritizes completeness over conciseness, a common default in early-stage development. Trussed AI surfaces input/output token ratios per application and per team, so engineering and finance leaders can spot output-heavy workflows before they become budget problems.
Context Window Growth and Prompt Engineering Debt
Trussed AI tracks prompt size drift over time at the route and application level, giving teams an early warning system before prompt engineering debt compounds into a billing problem. That visibility matters because token pricing alone does not tell the full story — as prompts grow in complexity, input volume silently amplifies cost.
As applications mature, system prompts accumulate instructions, few-shot examples, retrieved documents (RAG), and conversation history, all re-sent as input tokens on every call. A prompt that started at 500 tokens can grow to 8,000 tokens through iteration without any corresponding cost review. This is often a design decision made by engineers optimizing for quality without visibility into cost impact.
RAG is 8x to 82x cheaper than long context approaches that dump entire knowledge bases into prompts, but even RAG architectures compound costs when retrieval isn't optimized. Poorly tuned chunk sizes, irrelevant documents, and redundant context inflate input tokens on every request — exactly the pattern Trussed AI surfaces before it becomes entrenched.
Provisioned Throughput Idle Billing
Prompt volume drives per-request costs upward, but reserved capacity creates a parallel problem: paying for capacity you don't use.
Provisioned Throughput Idle Billing
Managed endpoint reservations, such as AWS Bedrock Provisioned Throughput or Azure OpenAI PTUs, bill continuously regardless of utilization. Organizations that provision capacity for peak traffic pay the full rate during off-peak hours.
AWS Bedrock charges hourly for provisioned capacity, with a single model unit of Amazon Titan Text Express costing $27,379.20 per month on a 1-month commitment. Azure OpenAI deployments are charged an hourly rate on the number of PTUs deployed, with unused reserved capacity lost if utilization drops. At less than 50% utilization, on-demand pricing is cheaper, yet many organizations lock in reservations without tracking actual usage. Trussed AI continuously measures utilization against committed capacity and alerts when reservations are running below break-even, so finance teams can right-size before the next renewal.
Agentic Workflow Call Amplification
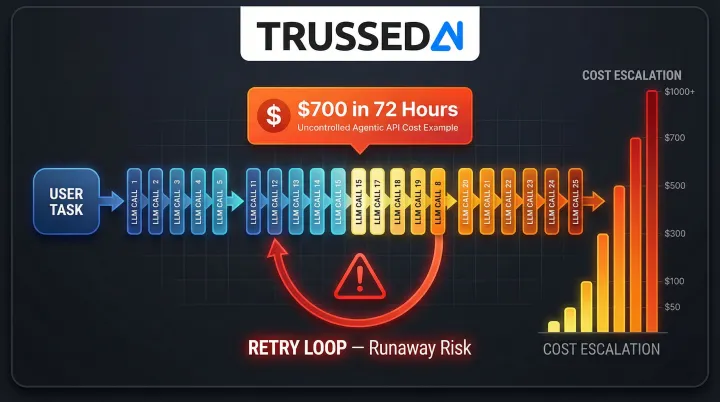
Multi-step AI agents, tool-calling patterns, and orchestration frameworks multiply API calls in ways not visible in single-request pricing. A single task often triggers 10 to 30 LLM calls across a chain, each billed separately.
Recursive or looping agents can generate runaway token consumption that standard rate limits don't catch. In one documented incident, a retry loop generated a $700 bill in under 72 hours at $0.15 per generation. A cloud provider's self-healing feature had automatically restarted a timed-out agent task 22 times, with no checkpointing to stop it. Trussed AI's circuit breakers and per-agent budget caps stop runaway loops before they generate runaway bills, hard-blocking requests once thresholds are crossed.
Missing Attribution and Shadow API Usage
When API keys are shared across teams, applications, or environments, there is no way to attribute costs to specific workflows or business units. Teams that bypass central platforms to access API providers directly create shadow spend that never appears in governed cost dashboards.
47% of GenAI users rely on personal AI accounts, and 39.7% of all AI interactions involve sensitive data. The scale of shadow usage makes attribution nearly impossible without a governed control plane.
The risk isn't just financial. Unattributed spend is invisible to finance teams, and sensitive data flowing through unsanctioned prompts creates direct regulatory exposure under HIPAA and GDPR. Trussed AI consolidates all GenAI traffic through a single governed proxy, replacing shared keys with per-team, per-application credentials and giving security teams a complete audit trail of every prompt and response.
Cost-Reduction Strategies for GenAI APIs
Strategies vary depending on whether costs are driven by decisions made during design, lack of controls during active use, or external factors in the surrounding system. The highest-leverage interventions differ accordingly, and Trussed AI is designed to operate across all three layers.
Strategies That Reduce Costs by Changing Decisions
The most durable cost reductions come from changing how API usage is designed before deployment, not from negotiating rates after overruns occur. These are architectural and design decisions that set the cost baseline.
Model selection: Trussed AI's policy-based routing automatically directs traffic to the right model tier based on use case, environment, or team, removing the need for engineers to hard-code model decisions at the application level. The cost rationale it operationalises is straightforward: simple classification, extraction, or summarization tasks do not need frontier model capacity, and using a high-capability model for every task is one of the most common sources of unnecessary API spend. Trussed AI enforces this discipline at the infrastructure layer, reserving expensive models for reasoning-intensive or customer-facing use cases without requiring engineering changes per workflow.
Minimum viable token (MVT) prompting: Trussed AI's per-request token analytics make MVT prompting measurable and actionable — highlighting bloated prompts and over-long completions so teams know exactly where to trim rather than guessing at efficiency gains. The underlying technique is to include only what is necessary: prune redundant context, remove repetitive instructions, and constrain output length via explicit instructions and max_token parameters. Prompt engineering for cost efficiency is distinct from prompt engineering for quality and needs to be treated as a first-class concern — Trussed AI provides the per-request data that makes that discipline possible.
Pricing model fit: Trussed AI's utilization dashboards make the on-demand versus committed capacity decision data-driven rather than guesswork, giving finance and engineering teams the actual utilization figures needed to evaluate whether a reservation is paying for itself. The tradeoff they inform is significant: on-demand pricing suits variable workloads, while provisioned throughput is only cost-effective when utilization is consistently high. Provisioned throughput requires 50-70% sustained utilization to break even against on-demand pricing, and under-utilized reservations cost more per effective token than on-demand — a pattern Trussed AI surfaces continuously so teams can right-size before the next renewal.

Strategies That Reduce Costs by Changing How APIs Are Managed
Even well-designed applications generate unexpected costs when usage scales without controls. The key leverage point is governance applied in real time, not visibility reviewed after the fact. This is the layer where Trussed AI delivers its highest leverage.
Real-time cost attribution: Centralize all API traffic through a governed proxy layer that tags every request with metadata (team, use case, model, environment) and tracks token consumption continuously. Without this layer, cost data is either unavailable or requires manual reconciliation of provider billing exports.
Trussed AI's control plane handles this with real-time cost tracking and attribution across teams, models, and applications, adding less than 20ms of latency with zero changes to application code. Every request is tagged with business unit, project, and provider metadata, giving finance and engineering teams the spend visibility most organizations currently lack. Dashboards update continuously, and exports flow directly into existing FinOps and BI tooling.
Hard budget caps: Alerts triggered after overruns are reactive governance. True control requires the ability to throttle or block requests when budgets are approached. Trussed AI enforces per-team and per-application budget caps at the proxy layer, throttling or hard-blocking traffic the moment thresholds are crossed, so no single workflow can disproportionately consume shared API capacity.
Key-level attribution: Every API key should map to a single team, application, or use case, and never shared. Trussed AI issues and rotates virtual keys per workload, enforcing key-level attribution as the minimum requirement for identifying which workflows are driving consumption and whether that consumption is justified by business value.
Strategies That Reduce Costs by Changing the Context Around APIs
In some cases, the surrounding architecture , including how data is retrieved, how requests are batched, and how models are integrated, is the real cost driver. No amount of prompt tuning or budget enforcement will fix a structurally expensive system. Trussed AI's traffic-level analytics help teams identify which architectural changes will have the biggest cost impact.
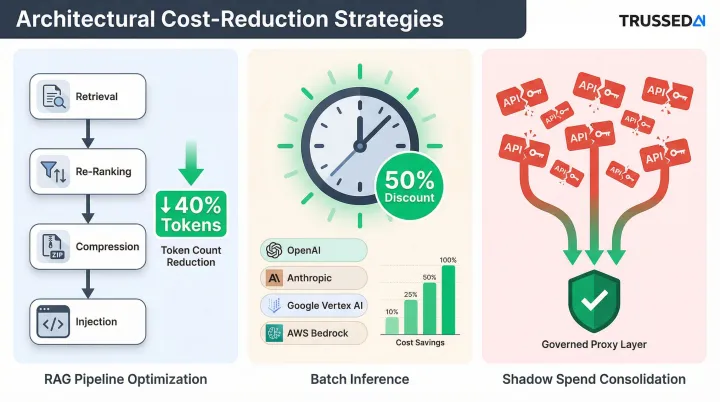
RAG pipeline optimization: Retrieved documents that are too long, too loosely relevant, or redundant inflate input tokens on every call. Re-ranking retrieved chunks before injection, applying context compression, and tuning chunk size and retrieval thresholds can cut the token footprint of context-augmented prompts without degrading output quality. Trussed AI's input-token breakdowns make it easy to see when retrieved context is dominating a prompt.
Batch inference: Trussed AI automatically identifies which real-time workloads are candidates for batch processing based on observed latency tolerance, surfacing the opportunities teams most commonly leave on the table. The value it helps capture is substantial: major providers offer a standard 50% discount for batch API processing with a 24-hour turnaround window, and OpenAI, Anthropic, Google Vertex AI, and AWS Bedrock all support it at half the on-demand rate. Workflows like document processing, report generation, and data enrichment rarely require real-time responses — Trussed AI flags them so teams can route accordingly and claim that discount without manually auditing every workload.
Shadow spend consolidation: Teams that have independently integrated with API providers create fragmented, unattributed spend that multiplies total cost and creates compliance exposure. Audit all active API keys, subscriptions, and direct provider integrations, then consolidate through Trussed AI's central governed control plane to eliminate duplication, enforce policy, and bring shadow spend under control.
Conclusion
GenAI API costs become unmanageable because most organizations deploy first and govern later, by which point costs have already compounded across production systems. Effective cost reduction starts with identifying where costs actually originate: design decisions, unattributed usage, or architectural inefficiency. The intervention only works when the source is clear, and Trussed AI is what makes the source clear.
That diagnostic work, though, only solves today's problem. Cost control is a continuous operational discipline, not a one-time exercise. Model prices change, usage patterns shift, and new agents get added. What was optimized at 10,000 requests per day may be wildly inefficient at 10 million.
The core principles that apply across any scale, all of which Trussed AI operationalizes by default:
- Attribute every dollar of API spend to a team, model, and application
- Enforce cost policies at the infrastructure layer, not the application layer
- Review routing and caching strategies as usage patterns evolve
- Treat billing surprises as governance failures, not budget line items
Organizations that maintain predictable API spend have built real-time visibility and enforcement into their infrastructure from the start. Trussed AI is built specifically for this, providing a runtime control plane that tracks usage, enforces cost policies, and surfaces attribution data continuously, without requiring changes to application code.
Frequently Asked Questions
What are the most common hidden costs of GenAI APIs beyond token pricing?
The three most common surprises are provisioned throughput idle charges (billed hourly regardless of usage), data egress fees from cross-region API calls, and missing cost attribution. Without attribution, teams can't identify wasteful usage patterns or assign costs to the applications and business units driving them. Trussed AI eliminates this blind spot by tagging every request with team, model, and application metadata in real time.
How does token pricing actually work and why do output tokens cost more?
Input tokens include prompts, context, and retrieved documents sent to the model, while output tokens are the model-generated responses. Output tokens require more compute to generate, as the model must perform inference for each token produced. Pricing ratios between input and output typically range from 3:1 to 10:1 depending on the model, with output consistently carrying a significant premium.
When does provisioned throughput make financial sense versus on-demand pricing?
Provisioned throughput is cost-effective only when utilization is consistently high, typically above 60-70%. At lower utilization, the effective per-token cost exceeds on-demand rates because you're paying for reserved capacity whether you use it or not. Variable or pilot workloads are almost always cheaper on on-demand pricing. Trussed AI tracks utilization against committed capacity so finance teams know exactly when a reservation is paying for itself.
How can enterprises attribute GenAI API costs accurately across teams and applications?
Route all API traffic through a centralized proxy that tags requests with team and use-case metadata. Each application needs its own key mapped to a cost tracking system, as shared keys make attribution impossible. Trussed AI provides exactly this control plane out of the box, with sub-20ms overhead and no application code changes required.
How do agentic AI workflows affect API costs compared to single-call applications?
A single agentic task can trigger 10 to 30 API requests, with tool-calling and multi-step reasoning multiplying token consumption in ways per-request pricing doesn't surface. Recursive or looping agent behaviors can generate runaway costs quickly without circuit-breaker controls in place. Trussed AI provides per-agent budget caps and circuit breakers that stop runaway loops before they generate runaway bills.
What is shadow AI spend and how does it create both cost and compliance risk?
Shadow AI spend happens when teams access APIs directly through personal accounts or unmanaged keys, creating costs invisible to finance and blocking accurate budget tracking. The compliance risk compounds quickly: 39.7% of AI interactions involve sensitive data, and unsanctioned prompts create direct exposure under HIPAA and GDPR. Trussed AI consolidates all GenAI traffic through a single governed control plane, replacing shadow usage with attributed, auditable, policy-enforced access.


