
Introduction
Enterprise generative AI adoption has made AI API costs a top engineering concern. Despite massive investment across organizations, engineering teams keep facing surprise invoices and budget overruns. One documented incident saw an autonomous agent loop 8,127 times in just four hours, generating a $340 bill for what should have been a simple task.
AI API costs behave differently from traditional cloud infrastructure in ways that make standard budget controls useless:
- Token-based billing creates volatility that fixed-rate models can't predict
- Output tokens cost 4–8x more than input tokens across major providers
- Multi-step agentic workflows can exhaust budgets in minutes with no natural stopping point
- Most LLM APIs provide minimal cost attribution, making it hard to trace which team, feature, or workflow is driving spend
Open-source, code-level cost control tools now fill this gap directly. Operating as gateways, observability layers, compression libraries, ML routers, and caching engines, these tools give engineers control over AI spend before, during, and after every API call.
Key Takeaways
- AI API costs are unpredictable due to token-based billing that varies by model choice, prompt length, and output length
- Five open-source tools address distinct cost levers across the API call lifecycle
- LiteLLM enforces hard budgets, Langfuse provides cost observability, LLMLingua compresses prompts, RouteLLM handles intelligent model routing, and GPTCache eliminates redundant calls
- All five tools integrate as proxies or SDKs with no changes to application code
- Trussed's Full Cost Control Platform sits as a governance layer on top of these tools - the tools handle cost mechanics, Trussed adds policy enforcement, cost visibility, attribution, enforcement, and model routing at the enterprise level
Why AI API Costs Spiral Out of Control
Token-based billing creates fundamental unpredictability. Unlike virtual machines with fixed hourly rates, every LLM call's cost depends on input length, output length, and model tier. The pricing penalty for output tokens is severe: OpenAI charges 4.0x more for output than input, Anthropic charges 5.0x more, and Google Gemini charges up to 8.33x more.
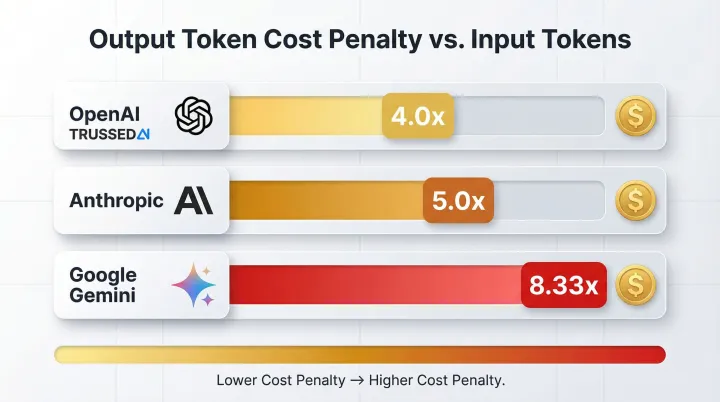
Two factors compound this unpredictability in production AI systems:
- Context window bloat: Stateless LLMs require resending full conversation histories with each turn. You're effectively paying for all previous messages repeatedly as the conversation grows, so costs compound with each exchange.
- Agentic AI architectures: Autonomous agents that plan, use tools, and iterate can trigger hundreds of API calls in a single workflow. Without natural stopping points, these systems create "Denial of Wallet" scenarios where costs spiral before teams notice.
Controlling these costs is harder still because native provider attribution is fragmented:
- OpenAI provides only
userandprojectfields for cost tracking - Anthropic requires workspace IDs
- Google Vertex AI allows custom metadata labels but requires complex BigQuery SQL queries to analyze spending
This fragmentation makes it nearly impossible to trace which team, feature, or workflow is driving spend , which is precisely why open-source tooling has stepped in to fill the gap.
5 Open-Source Tools to Control Your AI API Costs
These tools were selected based on three criteria:
- Production readiness , actively used in enterprise environments, not just demos
- Community adoption , measured by GitHub stars, maintainer activity, and documented deployments
- Distinct cost strategies , each tool attacks a different part of the cost problem, making them composable rather than redundant
LiteLLM , Universal Gateway with Built-In Budget Enforcement
LiteLLM is the most widely adopted open-source LLM gateway with 42,200 GitHub stars. It provides a unified OpenAI-compatible interface to 100+ LLM providers including OpenAI, Anthropic, Azure, AWS Bedrock, and Google Vertex AI. The platform operates as a Python SDK or FastAPI proxy server and is used in production by companies including Rocket Money, Samsara, and Adobe.
LiteLLM's key differentiator is real-time spend tracking with hard budget enforcement. The proxy tracks spend per virtual API key, per user, per team, and per project. Engineers set hard budget caps using max_budget (USD value) and budget_duration (e.g., "30d") parameters that automatically block requests when exceeded,preventing runaway agents from generating surprise invoices.
The platform also supports tag-based cost attribution and fallback routing to cheaper models when primary providers fail.
| Key Features | Unified interface to 100+ providers; hard budget caps per key/team/project; tag-based spend attribution; fallback routing; rate limiting |
|---|---|
| Best For | Teams managing multiple LLM providers who need centralized budget enforcement and cost attribution across Solution |
| Limitations | Python's GIL can limit throughput at very high concurrency (300+ RPS); production teams report latency spikes and memory leaks past this threshold |
Langfuse , Cost Observability That Connects Spend to Business Outcomes
Langfuse is an open-source LLM engineering platform with 24,400 GitHub stars, providing full-stack observability including tracing, prompt management, and evaluations with automatic cost calculation.
Langfuse calculates cost at ingestion time by matching each generation's model identifier against a live pricing database covering all major providers. It handles pricing nuances most trackers miss,including tiered pricing, reasoning tokens, cached tokens, audio tokens, and custom model definitions for fine-tuned models. Critically, it connects cost to business context by tracing spend through multi-step chains and agent workflows, allowing engineers to identify exactly which pipeline step is the cost driver. This makes it the foundation of cost analytics for teams that need to trace spend to specific business outcomes.
| Key Features | Per-trace cost analytics; pricing-tier awareness for complex models; reasoning/cached token tracking; OpenTelemetry-compatible; drop-in Python @observe() decorator |
|---|---|
| Best For | Teams running multi-step pipelines or agents who need to understand which specific workflow stage is responsible for cost spikes |
| Limitations | Primarily an observability tool,it surfaces costs but does not enforce budgets or route requests; best paired with LiteLLM for enforcement |
LLMLingua , Prompt Compression Up to 20x by Microsoft Research
LLMLingua is an open-source prompt compression library with 6,000 GitHub stars, developed by Microsoft Research. It uses small language models to identify and remove non-essential tokens from prompts, achieving up to 20x compression with minimal performance degradation. The library integrates with LangChain and LlamaIndex, making it provider-agnostic.
LLMLingua reduces cost before the API call by shrinking what you send. Its three-stage pipeline allocates different compression rates to different prompt segments,instructions are preserved while context and examples are compressed more aggressively. Key characteristics:
- LLMLingua-2: BERT-level encoder that runs 3–6x faster than the original
- LongLLMLingua: Optimized for RAG pipelines where retrieved chunks dominate prompt length
- RAG impact: Compresses 4,000–8,000 token document chunks down to 800–2,000 tokens, yielding 60–80% cost reduction on context-heavy workloads
| Key Features | Up to 20x prompt compression; three-stage pipeline (budget controller, coarse, token-level); LLMLingua-2 for faster inference; LongLLMLingua for RAG optimization |
|---|---|
| Best For | RAG pipelines and long-context workloads where retrieved document chunks dominate prompt length and token costs |
| Limitations | Compression introduces a small quality tradeoff; research and test compression ratios for your specific use case before deploying to production |
RouteLLM , ML-Based Model Routing That Sends the Majority of Queries to Cheaper Models
RouteLLM, with 4,800 GitHub stars, was built by the LMSYS team at UC Berkeley (creators of the Chatbot Arena leaderboard). It uses trained ML classifiers to analyze each incoming prompt and route it to either a strong (expensive) model or a weak (cheap) model based on query complexity. The framework provides four pre-trained routers trained on Chatbot Arena preference data and is controlled by a single cost-quality threshold parameter.
Most LLM queries don't require the most expensive model. On the MT Bench benchmark, the matrix factorization router achieved 95% of GPT-4's performance while cutting costs by up to 85%. The cost-quality tradeoff is adjustable via a single threshold, giving engineers direct control over routing aggressiveness.
| Key Features | Four pre-trained routers (Matrix Factorization recommended); single threshold parameter controls cost-quality tradeoff; OpenAI-compatible interface |
|---|---|
| Best For | Applications with mixed query complexity (e.g., customer support, internal assistants) where a significant proportion of requests are simple enough for cheaper models |
| Limitations | Routes between exactly two models (binary routing); typically paired with LiteLLM for multi-provider management, budget enforcement, and fallbacks |
GPTCache , Semantic Caching That Eliminates Redundant API Calls
GPTCache, with 8,000 GitHub stars, was built by Zilliz (creators of Milvus vector database) and pioneered semantic caching for LLM queries. Unlike exact-match caching (which only hits on identical prompts), GPTCache converts queries into vector embeddings and uses similarity search to find semantically equivalent previous queries,so "What's the weather in NYC?" and "Tell me New York City's weather" return the same cached response without an API call.
GPTCache's modular architecture has five pluggable components,LLM adapter, embedding generator, vector store, cache storage backend, and similarity evaluator,making it adaptable to a wide range of infrastructure stacks.
The library is currently in maintenance mode and relies on the legacy openai==0.28 API. Teams on active stacks may prefer RedisSemanticCache via LangChain as a maintained alternative, particularly if already using Redis infrastructure.
| Key Features | Semantic (similarity-based) caching via vector embeddings; pluggable components (FAISS, Milvus, ChromaDB, Redis, SQLite, PostgreSQL); configurable similarity thresholds |
|---|---|
| Best For | Applications with recurring or semantically similar queries (e.g., FAQ bots, support agents) where exact-match caching would have low hit rates |
| Limitations | Currently in maintenance mode; uses legacy openai==0.28 API; teams on active stacks may prefer RedisSemanticCache via LangChain as a maintained alternative |
How to Stack These Tools Across Your AI Cost Control Lifecycle
Cost control works best as a layered lifecycle, not a single tool swap. Each phase targets a different point of waste:
- Before the API call , Reduce what you send: use LLMLingua for prompt compression and GPTCache to skip the call entirely through semantic caching.
- During the API call , Route intelligently and enforce budgets: deploy RouteLLM for model selection and LiteLLM for gateway enforcement and fallback routing.
- After the API call , Attribute and analyze spend: implement Langfuse for per-trace cost analytics tied to pipeline steps and business outcomes.
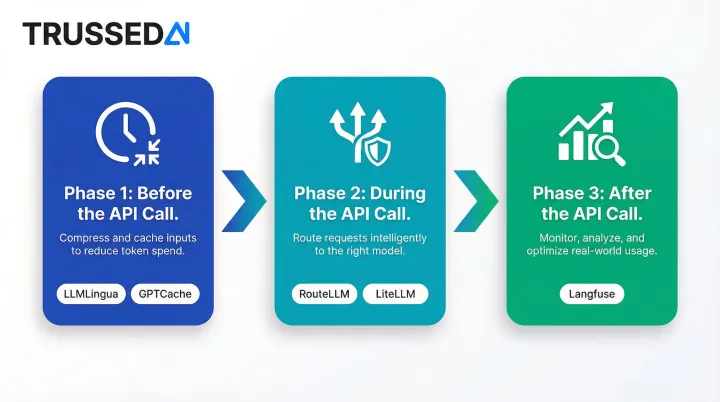
The most common two-tool starting point for teams new to programmatic cost control is LiteLLM (budget enforcement + multi-provider routing) paired with Langfuse (cost observability). This combination provides both a hard cost ceiling and the visibility needed to identify optimization opportunities,without changes to your application code beyond the proxy integration.
As deployments scale across multiple teams, models, and regulated workflows, the mechanics of cost control aren't enough on their own. These tools handle the mechanics well - but they don't automatically enforce policies, generate audit trails, attribute spend across teams and workflows, or govern AI behavior at runtime. That's where Trussed's Full Cost Control Platform comes in. Trussed sits as a governance layer on top of these five tools, adding policy enforcement, real-time cost visibility and attribution, budget enforcement across teams and projects, and intelligent model routing - capabilities that go beyond what any individual open-source tool provides on its own. Organizations that need those capabilities typically add a dedicated governance layer. Trussed AI's enterprise AI control plane covers that gap, providing real-time cost tracking and attribution alongside policy enforcement and compliance monitoring.
How We Chose These Tools
Tools were assessed on four criteria:
- Community adoption and production maturity , GitHub stars, enterprise usage, active maintenance
- Distinct cost control strategy , each tool targets a different lever: enforcement, observability, compression, routing, or caching
- Integration compatibility , OpenAI-compatible APIs, LangChain/LlamaIndex support, proxy-based deployment
- Open-source license permissiveness , MIT or Apache 2.0 for commercial use
The most common selection mistake is treating cost control as a single-tool problem. A gateway alone leaves you blind to usage patterns; observability alone gives you no way to enforce limits. These tools were chosen because they're composable , each covers a distinct phase of the API call lifecycle and can be deployed together without overlap.
Conclusion
AI API cost management is now an engineering discipline, not just a finance function. Open-source tools have made it practical to implement cost governance directly in code, at the same level of maturity that FinOps brought to cloud infrastructure.
Start with the combination that matches your current pain: if the problem is surprise invoices, start with LiteLLM; if the problem is no visibility, start with Langfuse; if RAG pipeline costs are the issue, add LLMLingua. The tools are modular and can be adopted incrementally.
Open-source tools cover a lot of ground, but they stop short of enforcing governance across AI apps, agents, and developer workflows as a unified runtime layer. The five tools covered here handle the mechanics - budgets, routing, compression, caching, and observability. Trussed's Full Cost Control Platform is the governance layer that sits on top: it adds policy enforcement, real-time cost visibility and attribution across every team and workflow, budget enforcement at the organizational level, and intelligent model routing. For enterprise teams operating in regulated environments, that distinction matters. Trussed AI is built specifically for that scope , providing real-time cost attribution, policy enforcement, and compliance monitoring across your entire AI stack, not just at the code level.
Frequently Asked Questions
What is the best open-source tool for enforcing hard budget limits on AI API spend?
LiteLLM is the most production-ready option for hard budget enforcement, with per-key, per-team, and per-project caps that automatically block requests when exceeded. It's the primary choice for preventing runaway agent spend.
Can these five open-source tools be used together in a single AI stack?
Yes, these tools are designed to be composable. LiteLLM and RouteLLM handle the gateway and routing layer; LLMLingua and GPTCache reduce what reaches the API; and Langfuse provides observability across all of them. There are no architectural conflicts between the tools.
How does semantic caching (GPTCache) differ from the prompt caching built into OpenAI's API?
OpenAI's prompt caching matches exact token sequences at the beginning of a prompt and requires prompts over 1,024 tokens, while semantic caching converts queries to embeddings and matches by meaning,so paraphrased or semantically equivalent questions return cached responses without any API call at all.
How much can LLMLingua realistically reduce costs on RAG workloads?
In RAG pipelines, retrieved document chunks often dominate token counts. LLMLingua can compress these from thousands of tokens down to a fraction of the original length, achieving 60–80% cost reduction in context-heavy workloads. Actual savings vary based on the compression ratio and quality threshold you configure.
Is LiteLLM production-ready for enterprise use, or is it primarily a developer tool?
LiteLLM runs in production at companies including Rocket Money, Samsara, and Adobe. It supports enterprise features like virtual API keys, tag-based attribution, rate limiting, and fallback routing. Very high-concurrency deployments (300+ RPS) may need a lower-level gateway paired in for the hot path.
What do open-source cost control tools not cover that enterprises should be aware of?
Open-source tools address the mechanics of cost control (budgets, routing, compression, caching, observability) but do not provide runtime policy enforcement, compliance audit trails, or governance across multi-team and regulated environments. Those capabilities require a dedicated enterprise governance layer - like Trussed's Full Cost Control Platform - that sits on top of these tools and adds policy enforcement, cost visibility and attribution, and intelligent model routing at the organizational level.


