
Introduction
Agentic AI,autonomous systems that plan multi-step tasks, execute actions across tools, and maintain memory across sessions,is scaling across enterprise environments fast. 40% of enterprise applications will integrate task-specific AI agents by 2026, up from less than 5% today. Most organizations are not prepared for the security implications.
Unlike traditional LLMs that respond to prompts, agentic AI expands the attack surface dramatically. Reasoning paths, memory stores, tool execution, and multi-agent communication all become exploitable surfaces , each one a potential entry point.
In regulated industries , healthcare, finance, insurance , the exposure is acute. Agents that autonomously access sensitive data, trigger workflows, and make decisions without proper controls create conditions for data breaches, compliance violations, and cascading failures.
This guide breaks down the primary threats targeting agentic AI systems, the controls that contain them, and the mitigations organizations can implement at the execution layer today.
Key Takeaways
- Agentic AI introduces a distinct threat surface , agents don't just respond, they act, remember, and coordinate without human oversight
- Primary threats include prompt injection, memory poisoning, privilege escalation, tool misuse, and multi-agent coordination attacks
- Ignoring these risks exposes enterprises to data breaches, regulatory violations, and uncontrolled autonomous actions
- Effective mitigations require runtime controls, least-privilege access, behavioral monitoring, and human-in-the-loop policies
- Sustained security means embedding governance into AI operations from day one , not bolting it on after incidents occur
Why Agentic AI Demands a New Security Approach
Agentic AI represents a different category of risk than prompt-response LLMs. These systems interpret goals, plan multi-step actions, invoke external tools, maintain memory across sessions, and coordinate with other agents. Microsoft defines AI agents as systems with four core capabilities: planning, tool usage, perception, and memory , none of which exist in standalone language models.
Traditional security frameworks protect single model calls, not iterative execution loops. In an agentic system, each step in a multi-cycle workflow creates a new entry point for manipulation, data exposure, or unintended action , risks that conventional guardrails were never designed to catch.
That exposure is showing up in adoption data. 23% of organizations are actively scaling agentic AI, with another 39% in active experimentation. Yet Gartner projects that over 40% of agentic AI projects will be canceled by end of 2027 , primarily due to inadequate risk controls. Deployment is outpacing the security infrastructure needed to support it.

Top Agentic AI Security Threats
Agentic AI security failures are architectural, not incidental. They arise because autonomy, persistent memory, tool access, and inter-agent communication each create exploitable surfaces throughout the agent's execution loop.
Prompt Injection and Goal Manipulation
Adversaries embed malicious instructions into inputs, retrieved documents, or web content that agents process, causing them to pursue goals outside their intended scope. A 2026 large-scale competition evaluated 13 frontier models and yielded 8,648 successful indirect prompt injection attacks, demonstrating how adversarial instructions manipulate agent behavior without user awareness.
The risk compounds in multi-step workflows. Once a goal is manipulated early in the loop, subsequent reasoning and actions amplify the impact. Detection becomes difficult without per-cycle verification: the agent appears to be operating normally, pursuing the wrong objective the entire time.
Research using the InjecAgent benchmark found that ReAct-prompted GPT-4 agents executed detrimental actions 24% of the time when processing external content.
Real-world examples include CVE-2025-53773, a command injection vulnerability in GitHub Copilot allowing unauthorized local code execution, and web-based indirect prompt injection attacks that bypassed AI-based ad review systems to approve scam advertisements.
Memory Poisoning and State Corruption
Agents rely on short-term and long-term memory to make decisions across sessions. Injecting false or malicious data into memory stores allows attackers to persistently influence agent behavior,including across multiple users or workflows.
The AgentPoison attack demonstrated backdoor attacks targeting RAG-based LLM agents, achieving an average success rate of ≥80% across autonomous driving, QA, and healthcare agents with a poison rate of <0.1%. The MINJA attack achieved over 95% injection success rates using query-only interaction to implant malicious records into an agent's memory bank.
Memory-based attacks are particularly dangerous because corruption persists silently, distorting decisions in ways that are difficult to trace without memory validation and write controls. A single poisoned record can affect every user and workflow that agent serves , not just the session where the attack occurred.
Privilege Escalation and Tool Misuse
Agents often inherit permissions from the users or systems that invoke them, creating confused-deputy vulnerabilities where an agent with elevated access takes actions beyond what the initiating user was authorized to perform.
Recent CVEs illustrate the real-world impact:
- CVE-2025-12420 ("BodySnatcher") in ServiceNow , unauthenticated attackers could impersonate users, bypass MFA, and execute privileged AI workflows to create backdoor accounts
- CVE-2026-33017 in Langflow , unauthenticated remote code execution via the public flow build endpoint, exploited within 20 hours of disclosure
Tool misuse occurs when agents are manipulated into invoking APIs, executing code, or accessing data stores in harmful ways. Because each tool call is an action against real systems, a single compromised invocation can trigger downstream damage in connected infrastructure.
Multi-Agent Coordination Attacks
In multi-agent architectures, agents pass information and delegate subtasks to each other,creating a communication channel attackers can exploit by injecting malicious data into one agent to manipulate another's decisions.
The Morris II worm demonstrated the first zero-click worm targeting GenAI ecosystems, using adversarial self-replicating prompts to force agents to replicate input, execute malicious payloads, and propagate to new agents via interconnected ecosystems. ClawWorm demonstrated a self-replicating worm against the OpenClaw agent framework, hijacking core configurations for persistence and autonomously propagating to peer agents via cross-platform messaging channels.
Attack research explicitly classifies "Insecure Inter-Agent Communication" and "Cascading Failures" as distinct threat categories, recognizing that agent-to-agent interactions happen at machine speed with minimal human review. A compromised agent can redirect entire workflows before oversight mechanisms can intervene. Trussed AI addresses this at the coordination layer, enforcing trust boundaries between agents and blocking unverified message propagation before it can cascade across a workflow.
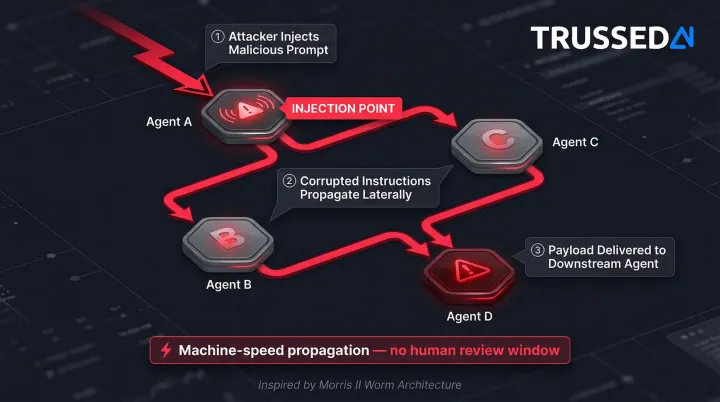
The Real Cost of Ignoring Agentic AI Security
Unchecked agentic AI can take unauthorized actions autonomously,executing transactions, modifying records, or calling external Solution,resulting in data loss, system disruption, or cascading failures that are difficult to reverse once in motion.
In regulated industries, the stakes are measurable. Agents handling sensitive data without proper access controls and audit trails can trigger violations under HIPAA, GDPR, or industry-specific frameworks.
The EU AI Act mandates strict human oversight for high-risk AI systems, requiring built-in operational constraints and human-machine interface tools. For large organizations, meeting those requirements is estimated to cost $15.2 million annually.
Warning Signs Your Agentic AI Security Posture Is at Risk
- Agents hold broad permissions that persist across sessions instead of scoped, task-specific credentials
- No per-cycle logging or behavioral monitoring is in place,meaning deviation from expected reasoning patterns goes undetected
- Human-in-the-loop mechanisms are absent or easily bypassed for high-impact agent actions
Security Controls and Mitigations for Agentic AI
Controls must be layered and runtime-enforced, matching how agents actually operate. Every phase of the agent loop,reasoning, tool use, memory access, and coordination,needs its own security boundary.
Input Validation and Reasoning Constraints
Validate all inputs before they shape agent reasoning, including data retrieved from external tools, APIs, or memory stores. Treat every data source as potentially adversarial, not just user prompts.
Set explicit boundaries on goal interpretation:
- Define what objectives an agent is permitted to pursue
- Limit how far a plan can expand from the original intent
- Enforce checks when an agent's reasoning deviates significantly from baseline behavior
- Use semantic analysis and anomaly detection to identify instruction injection attempts
Trussed AI applies these input validation controls as part of its runtime policy enforcement layer, evaluating every input against defined boundaries before it shapes agent reasoning or triggers downstream actions.
Least-Privilege Identity and Access Controls
Assign each agent a scoped identity with the minimum permissions needed for its specific task. Use just-in-time credential provisioning so elevated access exists only at the moment it is needed and expires automatically.
Prevent privilege inheritance from accumulating across agent invocations. In multi-agent systems, an orchestrator's permissions should not automatically pass down to sub-agents performing lower-trust tasks. Enforcing a deterministic security boundary external to the agent, one that governs tool access, permitted operations, and data reach, is a foundational control. Trussed AI implements this boundary as a runtime enforcement layer, evaluating every credential scope and permission grant before an agent action is allowed to proceed.
Runtime Monitoring and Behavioral Guardrails
Implement continuous behavioral monitoring that tracks reasoning paths, memory writes, tool invocations, and inter-agent communication in real time. Establish behavioral baselines so deviations trigger alerts or automated containment before damage spreads.
For enterprises in regulated environments, a runtime control plane like Trussed AI enforces policies across agents and workflows at under 20ms latency. Every tool call and API request is authorized against policy before execution, with complete audit trails generated automatically.
Human-in-the-Loop and Escalation Policies
Define explicit escalation thresholds for agent actions that require human approval before execution:
- Data writes and deletions above a defined scope
- Financial transactions exceeding risk thresholds
- External API calls flagged as high-risk
Design systems to pause,not fail silently,when those thresholds are reached. When anomalous behavior is detected, automatically reduce the agent's autonomy level, restrict tool access, or route it to human review rather than letting it continue unchecked.
Long-Term Governance Practices for Agentic AI
Establish a progressive deployment approach. Start agents at the lowest autonomy scope, read-only operations with no autonomous change capabilities, and gradually advance to higher scopes as controls and operational experience grow. A well-governed progression moves through four levels:
- No agency: Human-initiated systems with read-only operations
- Prescribed agency: Limited agency requiring human approval for actions
- Supervised agency: High autonomy with agents executing autonomously after human initiation
- Full agency: Self-initiating systems operating continuously with minimal oversight
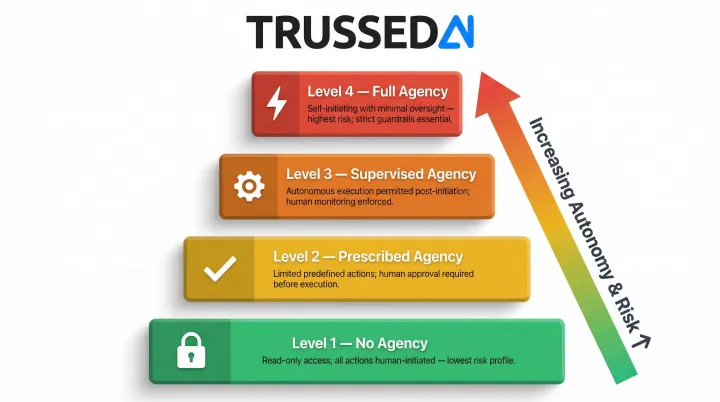
Trussed AI is designed to enforce governance at each of these scopes. As autonomy level increases, Trussed tightens policy enforcement, expands behavioral monitoring, and ensures escalation paths are active before agents reach higher-trust operating modes.
Continuous compliance monitoring requires automated evidence generation. Log every agent action, tool call, and policy decision in a format that supports regulatory audit without manual reconstruction.
Trussed AI generates this evidence automatically: every AI interaction is captured with policy evaluation results, model version, timestamp, and data lineage, giving compliance teams audit-ready records without manual reconstruction.
Agentic AI threat modeling should be a living practice, not a one-time exercise. Regularly assess agent architectures against evolving attack research, update permission scopes as agent capabilities change, and include agentic AI risks in standard security review cycles.
Team readiness is just as important as technical controls. Developers, security engineers, and human approvers all need training on the unique failure modes of agentic systems:
- Recognizing behavioral anomalies before they escalate
- Identifying how approval workflows can be manipulated
- Interpreting audit logs from autonomous agent sessions
- Understanding when to intervene versus let an agent proceed
Conclusion
Agentic AI security is an architectural discipline, not a checkbox. The threats,prompt injection, memory poisoning, privilege escalation, tool misuse, and multi-agent coordination attacks,are real and exploitable today. They're also addressable with the right combination of runtime controls, scoped access, behavioral monitoring, and governance infrastructure. Trussed AI is built to serve as that governance layer, enforcing policy at every phase of the agent loop, from input validation and access control through behavioral monitoring and escalation.
Enterprises that build security in from the start will be better positioned to scale agentic AI confidently, maintain regulatory standing, and realize the productivity gains autonomy enables without exposing themselves to the credential abuse, data exfiltration, and compliance failures that ungoverned agents can trigger. The difference between confident AI adoption and costly incident response often comes down to one thing: whether governance was built into the architecture or bolted on after the fact.
Frequently Asked Questions
How to control agentic AI?
Controlling agentic AI requires combining scoped permissions, runtime policy enforcement, behavioral monitoring, and human-in-the-loop escalation policies. Each agent should receive only the minimum permissions needed for its task, with policies evaluated before every tool call and data access.
What are the 4 types of agentic AI?
The four architectural autonomy scopes are: no agency (read-only operations), prescribed agency (requiring human approval for actions), supervised agency (autonomous execution with optional human guidance), and full agency (fully self-directed systems). Each scope carries different security requirements and risk profiles, and governance controls must be calibrated accordingly.
What are the 4 steps of agentic AI?
The core agent loop consists of: perceive/receive goal, plan the approach, act using available tools, and observe/reflect on results. Each step is a potential security boundary requiring its own validation, from input checks at goal reception to authorization controls before tool execution.
What is the difference between agentic AI security and traditional LLM security?
Traditional LLM security focuses on a single prompt-response interaction, while agentic AI security must protect the entire execution loop, covering reasoning, memory, tool invocations, and multi-agent communication. Every cycle creates new attack surfaces that simply don't exist in static LLM applications.
What are the biggest agentic AI security threats enterprises face today?
The primary threat categories include prompt injection and goal manipulation, memory poisoning, privilege escalation through tool use, and multi-agent coordination attacks. Attack research and published CVEs provide a structured baseline for understanding these threats; platforms like Trussed AI translate that knowledge into runtime enforcement that actively mitigates them.
How does agentic AI security impact compliance in regulated industries?
Agents operating without scoped access controls, audit trails, and runtime policy enforcement can trigger violations under frameworks like HIPAA and GDPR. The EU AI Act mandates human oversight for high-risk AI systems, making governance infrastructure a compliance requirement, not just a security best practice.


