
Introduction
As AI systems multiply across enterprise environments, understanding where data comes from, how it transforms, and how it feeds AI decisions has become mission-critical, yet most organizations still rely on manual, fragmented documentation that cannot keep pace. According to Gartner, poor data quality costs organizations an average of $12.9 million annually, while a 2024 Deloitte survey found that data-related issues caused 55% of organizations to avoid certain Generative AI use cases entirely.
AI-powered data lineage is the automated tracking of a dataset's complete journey, from origin through every transformation, using machine learning and AI inference. When manual documentation fails at scale, automated lineage becomes the foundation of trustworthy AI.
TLDR:
- AI-powered lineage automatically maps data flows from source to AI model using ML inference, not manual documentation
- Reduces root-cause analysis from days to minutes by tracing errors backward through pipeline layers
- Generates audit-ready compliance evidence automatically, satisfying GDPR, HIPAA, and EU AI Act requirements
- Scales across complex multi-cloud environments where manual lineage breaks down
- Runtime governance platforms extend lineage beyond pipelines to live AI model interactions and agent workflows
What Is AI-Powered Data Lineage?
Data lineage is the process of tracking how data flows from its source through all transformations to its final destination. The "AI-powered" distinction means that unlike traditional lineage, which depends on manual documentation or hand-annotated pipelines, AI-powered lineage automatically infers, maps, and updates data flows by analyzing queries, logs, ETL scripts, and metadata.
Concrete example: A bank's credit-scoring model pulls data from a loan applications table in a warehouse, which was populated by a nightly ETL job from a CRM system. AI-powered lineage automatically discovers this chain from source to transformation to model input, without anyone writing documentation, and keeps it current as pipelines evolve.
Core Components Data Lineage Tracks
Lineage captures five key metadata elements:
- Origins and timestamps: where data was created and when
- Transformations: filtering, aggregation, currency conversion, and joins applied along the way
- Dataset relationships: dependencies, hierarchies, derived tables, and copies
- Cross-system movement: the full path from source through staging, warehouse, BI tool, and AI model
- Consumption patterns: who or what accesses the data and how frequently
Manual Lineage vs. AI-Powered Lineage
Manual lineage requires developers to instrument pipelines, write metadata rules, and maintain documentation by hand. Across hundreds of data sources and millions of tables, that documentation becomes stale faster than teams can update it.
AI-powered lineage takes a different approach: inference algorithms, including code parsing, log analysis, and ML pattern matching, automatically deduce data flows, fill documentation gaps, and keep the lineage graph current without human intervention.
The key capability enabling this is inferred lineage: when no explicit documentation exists, the AI system makes an evidence-backed determination of the data flow, giving teams a queryable, visual map of connections they could never maintain manually.
Informatica's CLAIRE AI engine, for example, automatically infers one-to-one lineage relationships between source and target tables by analyzing naming conventions and observed patterns, bridging gaps where documentation is missing.
How AI-Powered Data Lineage Works: The Inference Engine
AI lineage tools ingest metadata from multiple sources, including SQL query logs, ETL job definitions, BI tool configurations, API calls, and schema change events, then use pattern-matching and machine learning to link data inputs to outputs across systems. The result is a continuously updated dependency graph, not a static diagram.
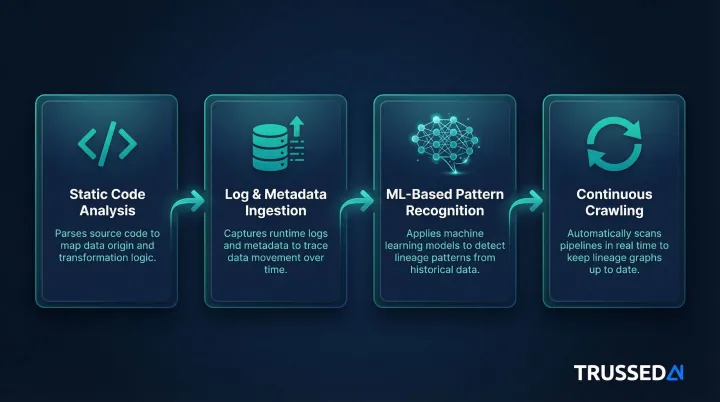
Four core techniques drive this inference process.
Key AI Techniques Behind Lineage Inference
Static code analysis parses SQL queries, dbt models, Python scripts, and ETL configurations to extract column-level input/output relationships. dbt's lineage feature reflects relationships from select statements in models' SQL code, surfacing hidden lineage that standard APIs don't expose.
Log and metadata ingestion observes actual data movements in production by pulling runtime logs and job execution records. Google Cloud Dataplex automatically records lineage from BigQuery copy, query, and load jobs, allowing the system to validate or correct statically inferred flows.
ML-based pattern recognition identifies relationships between datasets based on shared column names, structural similarity, and usage co-occurrence, inferring connections even where documentation is absent. Informatica's CLAIRE uses trained AI models to detect and build lineage between sources and targets, recommending or auto-accepting links based on confidence scores.
Continuous crawling keeps the lineage graph current rather than treating it as a point-in-time snapshot. OpenLineage supports streaming jobs by emitting continuous RUNNING events at configurable intervals, capturing mid-execution transformation changes and dataset updates in near real-time. Modern tools monitor for schema changes, new tables, deprecated pipelines, and updated transformations. The lineage map refreshes automatically so AI agents and data teams always work from accurate information.
Key Benefits of AI-Powered Data Lineage
AI-powered data lineage delivers measurable improvements across five areas that matter most to data and engineering teams.
Transparency in AI Outputs
When an AI model generates a decision, lineage lets users trace exactly which data sources were used, what transformations were applied, and whether those sources are certified and current. Without this visibility, AI outputs are unverifiable, and unverifiable outputs are a liability in regulated environments.
Faster Root-Cause Analysis and Impact Assessment
Engineers can trace errors backward through pipeline layers to the exact source in minutes rather than days. A Monte Carlo case study found that T. Rowe Price cut issue resolution time from 6 hours to 1 hour, an 83% reduction, using automated observability and lineage.
Before changing a data source or schema, teams can also immediately see which reports, dashboards, and AI models depend on that data. That impact map prevents downstream breakage before it happens.
Automated Compliance Evidence
Lineage tools generate audit-ready trails documenting data provenance, transformations, and access, satisfying regulatory requirements without manual reconstruction. The stakes are real: the 2024 IBM Cost of a Data Breach Report puts the global average breach cost at $4.88 million.
Bias Detection and AI Fairness
By tracing which datasets and features fed a machine learning model, data teams can identify whether an upstream source was skewed or contained discriminatory patterns, and correct those issues before deployment. The NIST AI Risk Management Framework explicitly ties training data provenance to both transparency and accountability.
Scalability Across Multi-Cloud Environments
Manual lineage breaks down at enterprise scale. A 2023 Matillion and IDG survey found that the average organization draws from 400 distinct data sources, with more than 20% managing 1,000 or more. AI inference keeps lineage intact across cloud and on-premises systems, regardless of how complex the pipeline gets.

Real-World Use Cases for AI-Powered Data Lineage
Root Cause Analysis in Analytics
A BI team detects an anomaly in a revenue dashboard: Q4 sales for the Northeast region dropped 40% overnight. Using the lineage graph, they trace the issue backward and immediately identify that a batch ETL job changed a filter on a regional sales table, excluding a key product category. What would have taken days of manual inspection is resolved in minutes.
ML Model Governance
A regulated financial institution must demonstrate to auditors that a credit-scoring model was trained exclusively on anonymized, approved datasets. Using lineage, they link the final model artifact back to its source tables, transformation steps, and training parameters. Compliance is proven without manual reconstruction, and the regulatory review proceeds on schedule.
Impact Analysis Before System Changes
Data engineers need to change a customer ID format from integer to UUID across the data warehouse. Before touching anything, they query the lineage graph for downstream dependencies. The results are concrete: 47 reports, 12 dashboards, and 3 AI models all reference that field. With a full dependency map in hand, they coordinate updates across every affected system, with no surprise failures and no unplanned rollbacks.
Agentic AI Context and Safety
AI agents query lineage at runtime to verify data provenance and quality before acting on that data. This ensures agents reason only over certified, governed sources, not deprecated datasets or unvalidated inputs. In autonomous AI workflows, that verification step directly reduces the risk of compounding errors downstream.
AI-Powered Data Lineage and Regulatory Compliance
Data lineage is explicitly required, or strongly implied, by every major data regulation. Four frameworks make this especially clear:
- GDPR Article 30: Controllers must "maintain a record of processing activities," requiring documented understanding of how personal data flows through systems.
- HIPAA 45 CFR 164.312(b): Covered entities must implement "audit controls that record and examine activity in information systems" containing electronic protected health information.
- BCBS 239 Principle 3: Banks must "generate accurate and reliable risk data" with complete lineage across all reporting systems.
- EU AI Act Article 10: Training, validation, and testing datasets must follow data governance practices that account for "data collection processes and the origin of data."

AI-powered lineage converts compliance documentation from a manual reconstruction task into an on-demand audit record. Audit-ready evidence is generated as a byproduct of every governed data interaction, so teams access it when needed rather than scrambling to rebuild it.
That capability matters most where the stakes are highest. Insurance, healthcare, and financial Solution face the steepest penalties for data governance failures, and they also run the most complex data pipelines feeding AI models. The consequences of gaps in lineage are well-documented: in 2020, the UK ICO fined Marriott International £18.4 million for GDPR failures, citing inadequate security controls and no ongoing monitoring. A separate healthcare case made the cost even clearer. Anthem's $16 million HIPAA settlement in 2018 traced directly to failures in risk analysis documentation.
Enterprise AI governance platforms like Trussed AI extend lineage beyond the data layer into the AI runtime layer: enforcing policies at the point of every AI interaction and automatically generating audit trails, so compliance monitoring runs continuously rather than on a reporting schedule.
Implementation Challenges and How to Overcome Them
Deploying AI-powered data lineage at enterprise scale introduces friction at multiple layers, from how metadata is collected to how granular the lineage needs to be. Here are the most common obstacles and how to address them.
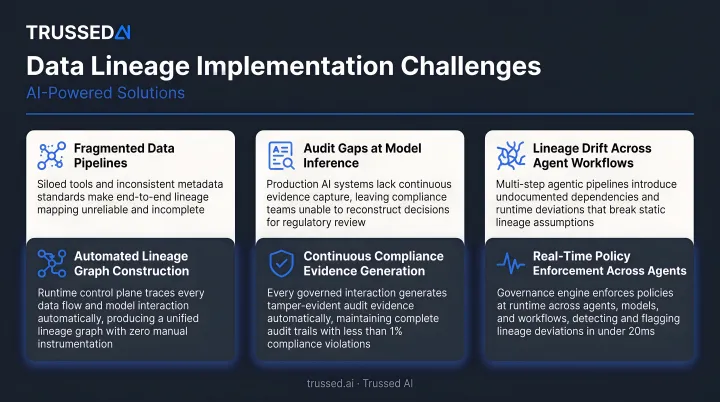
Fragmented Metadata Across Tools and Environments
Most enterprises carry lineage scattered across a warehouse, BI platform, transformation layer, and cloud Solution that don't natively talk to each other. The result is incomplete graphs with blind spots at every integration boundary.
A unified metadata layer solves this by integrating across the entire stack and stitching end-to-end lineage from a single control plane. It also propagates trust signals and quality metrics both downstream and upstream, so every team works from the same picture.
Lineage That Goes Stale in Dynamic Environments
Tables are added, renamed, and deprecated. Pipelines are refactored. Point-in-time lineage degrades quickly, and teams lose confidence in what they're looking at.
Continuous crawling and event-driven updates keep the lineage graph current. Instead of a historical record that teams have to second-guess, the graph becomes live infrastructure, reflecting the actual state of the data ecosystem at any moment.
Scaling to Column-Level Granularity
Table-level lineage is too coarse for debugging specific metric errors or proving compliance for individual data fields. The difficulty is that column-level relationships are often buried inside unparsed SQL or transformation code. Google Cloud Dataplex notes that "column-level lineage isn't collected if a job creates more than 1,500 column-level links," and Atlan advises that column-level lineage requires considerably more investment to implement and maintain.
AI-powered code parsing tools address this by automatically extracting column-level dependencies from transformation scripts, even when those relationships aren't exposed through standard APIs.
Frequently Asked Questions
What is data lineage with an example?
Data lineage maps the complete journey from source data to final output. For example, a sales dashboard traces back through an ETL aggregation job to a regional transactions table in a database, showing exactly where each number came from and what transformations were applied along the way.
How does data lineage work?
Data lineage tools capture metadata about data assets, including origins, transformations, movements, and relationships, either through manual documentation or, increasingly, through AI inference that automatically scans queries, logs, and code to build and maintain a live dependency graph.
Who needs data lineage?
Data lineage is essential across multiple roles:
- Data engineers: debugging pipelines and running impact analysis
- Governance teams: enforcing compliance policies
- Analysts: validating that results are trustworthy
- AI/ML teams: confirming model training data integrity
Regulated industries like healthcare, financial Solution, and insurance face the most urgent need due to compliance requirements.
What is the difference between data lineage and traceability?
Data lineage tracks the complete journey of data from origin through transformations to its current state. Traceability is a broader term: the ability to follow any data, process, or artifact back to its source. Lineage is the specific mechanism that makes traceability possible in data systems.
Which platforms provide traceability and lineage for AI data?
Key platforms include Google Dataplex/BigQuery, Informatica, IBM Watson Knowledge Catalog, Alation, Microsoft Purview, and Apache Atlas/OpenLineage. Dedicated AI governance control planes like Trussed AI go further, extending lineage tracking to the AI runtime and agent interaction layer, where policies are enforced in real time during execution.
What are the 4 pillars of data governance?
The four pillars are data quality, data security, data management (stewardship and lifecycle), and compliance/accountability. Data lineage underpins all four by providing visibility and auditability across the data estate, making it possible to prove quality, enforce policies, and demonstrate compliance.


