
Introduction
Most enterprises now run AI applications, agents, and workflows across production systems , but ongoing oversight rarely keeps pace with deployment. Model drift, policy violations, and cost overruns accumulate quietly until regulatory scrutiny or a visible failure forces the issue, by which point the damage is done.
Most teams treat deployment as the finish line. In reality, production is where governance, performance, and compliance work begins. RAND Corporation research estimates that more than 80% of AI projects fail to deliver their intended business value, with a significant share abandoned before they ever reach production.
For projects that do reach production, the challenges intensify. AI systems can fail silently — through drift, policy violations, or quality degradation — and human-managed oversight cannot operate at machine scale.
This guide covers how continuous AI system performance auditing shifts governance from reactive to real-time: detecting drift, policy violations, and quality degradation before they reach customers, regulators, or your bottom line.
Key Takeaways
- Continuous AI auditing monitors models, agents, and workflows in real time - catching drift, policy violations, and quality degradation as they happen, not months later
- Without it, enterprises absorb compounding compliance risk, unpredictable costs, and quality degradation that surfaces only after business damage is done
- A structured six-stage process drives the work: from scoping and baselining through continuous collection, automated analysis, alert triage, and documented action
- Key metrics include output quality scores, latency percentiles, policy violation rates, token costs by team and model, and drift indicators
- Platforms like Trussed AI enforce governance at runtime and generate audit-ready evidence automatically, eliminating manual compliance overhead
What Is Continuous AI System Performance Auditing?
Continuous AI system performance auditing is the ongoing, automated process of monitoring, evaluating, and documenting the behavior, output quality, cost, and compliance posture of AI systems in production,as opposed to periodic spot-checks or post-incident reviews.
This discipline is specifically about auditing the AI itself,its models, prompts, agents, pipelines, and guardrails,to ensure they remain accurate, safe, and compliant over time. It differs from traditional IT auditing, which focuses on static configurations and access logs, and from "using AI to audit other systems," which applies AI tools to monitor business processes.
Where Continuous AI Auditing Applies
The scope includes:
- Single-model APIs – Direct calls to LLM providers like OpenAI or Anthropic
- Multi-step LLM pipelines – Sequential workflows combining retrieval, generation, and validation
- Autonomous agentic workflows – AI systems that take actions, call tools, and access data independently
- Developer tool integrations – IDEs, SDLCs, and copilots embedded in engineering workflows
Each architecture presents different failure modes and governance requirements. Single-model APIs can drift without notice when providers update underlying models. Multi-step pipelines introduce compounding risk: a failure at any stage cascades downstream, making the source harder to isolate.
Agentic systems raise the stakes further. Every tool call and data access needs evaluation against policy before it executes,not after.
Why Continuous AI Auditing Is Critical for Enterprise AI Governance
AI systems are not static. Model updates from providers, shifts in input data distribution, and prompt changes can degrade output quality or introduce policy violations without warning. A peer-reviewed study published in Scientific Reports found that 91% of machine learning models degrade over time, yet most organizations lack the infrastructure to detect this drift before it impacts business outcomes.
The Regulatory Pressure Is Real
Regulated industries face growing requirements around AI explainability, audit trails, and bias monitoring. Key mandates include:
- EU AI Act: Requires automated event logging over the lifetime of high-risk systems, with logs retained for at least six months
- NIST AI RMF: Requires post-deployment monitoring plans with incident response and change management mechanisms
- Federal Reserve SR 11-7: Requires ongoing monitoring to confirm models perform as intended and are adjusted when market conditions change
Periodic reviews cannot satisfy these expectations when AI is making decisions continuously. When the Massachusetts Attorney General reached a $2.5 million settlement with Earnest Operations over AI underwriting models that allegedly resulted in unlawful disparate impact, it demonstrated the financial and reputational stakes of unmonitored AI systems.
The Operational and Financial Stakes
Unaudited AI systems generate unpredictable compute costs. Enterprises consistently report that AI infrastructure expenses erode gross margins, and that forecasting accuracy for AI spend is significantly worse than for traditional IT — driven by the volatility of token consumption, GPU utilisation, and model-pricing changes that can shift spending dramatically overnight.
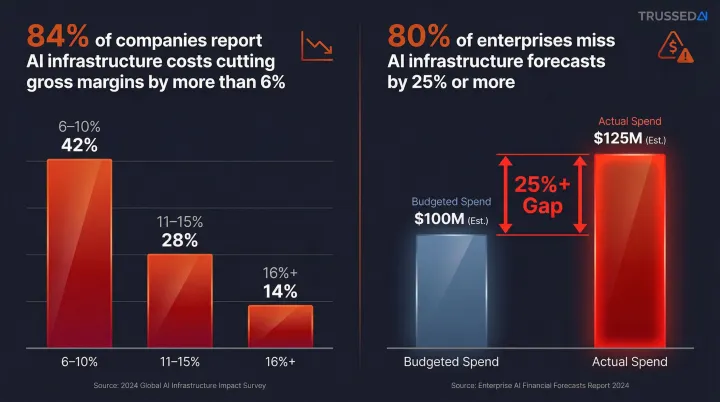
Beyond cost overruns, unaudited AI exposes organizations to liability from non-compliant outputs and erodes stakeholder trust. Continuous auditing is what separates organizations that manage AI risk from those that discover it too late.
How Continuous AI System Performance Auditing Works – Step by Step
This section maps the auditing process to real production environments. Teams commonly skip critical steps,baseline documentation, alert triage workflows, and remediation loops,creating governance gaps that only surface during audits or incidents.
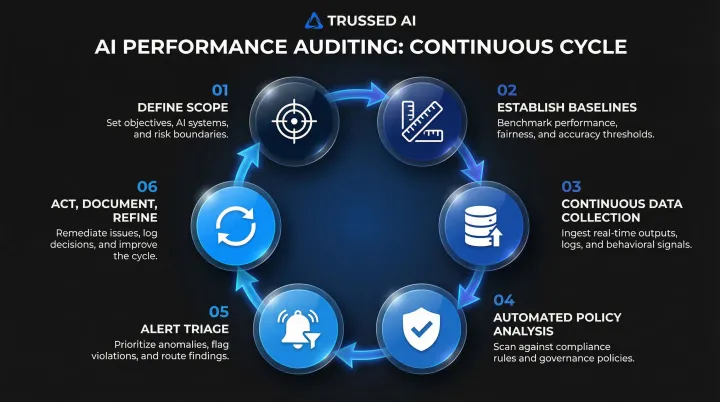
Step 1 – Define Audit Scope and AI System Boundaries
Identify which AI systems, models, agents, and workflows fall within the audit perimeter. Specify the business processes they touch and the compliance frameworks that apply.
Key activities:
- Document all production AI systems,applications, agents, developer tools, and workflows
- Map each system to business processes and data it accesses
- Identify applicable regulations: HIPAA for healthcare, GDPR for EU data, FERPA for educational institutions
- Establish accountability: which teams own each system, and who approves policy changes
Metrics impacted: Audit coverage completeness, regulatory alignment, stakeholder clarity on accountability.
Watch for this gap: Shadow AI deployments,tools and integrations adopted outside IT,are the most common audit scope failure. Without a documented perimeter, you're auditing what you know about, not what's actually running.
Step 2 – Establish Baseline Performance Benchmarks
Before continuous monitoring can flag anomalies, teams must document expected behavior. Define acceptable ranges for output quality, latency, cost per request, hallucination rates, and policy adherence under normal conditions.
Key activities:
- Run controlled tests to establish typical output quality and accuracy
- Measure baseline latency (p50, p95, p99) for each model and workflow
- Document expected cost per request by model and use case
- Establish acceptable policy adherence rates (e.g., <1% violation rate for safety guardrails)
- Record current hallucination rates and factual accuracy benchmarks
Metrics impacted: False positive rate in alerting, detection precision, speed of triage.
What teams commonly skip: Deploying monitoring without baselines is the most common cause of alert fatigue. Without documented expected behavior, every variation looks like a problem,and teams quickly learn to ignore the alerts.
Step 3 – Set Up Continuous Data Collection and Logging
Instrument every interaction: capture inputs, outputs, latency, model versions, cost, and any guardrail trigger events. A proxy-based approach,intercepting AI calls without code changes,is the lowest-friction method for enterprises with many integrated AI tools.
Key activities:
- Deploy a proxy layer that sits between applications and AI models
- Log every request and response with full metadata: timestamp, model version, latency, token count, cost
- Capture policy evaluation results and guardrail triggers
- Maintain data lineage showing how inputs flow through multi-step pipelines
- Ensure logs meet regulatory retention requirements (EU AI Act requires six months minimum)
Metrics impacted: Observability coverage, evidence completeness for compliance, data freshness for analysis.
What teams commonly skip: Sampling or logging only errors creates blind spots that look like clean records. When a regulator asks for evidence of a specific interaction from three months ago, sampled logs won't cut it,you need complete coverage.
Trussed AI's proxy-based integration sits between your applications and AI models, capturing every interaction with zero application code changes. This gives compliance teams a complete, queryable evidence layer without requiring engineering effort per integration.
Step 4 – Apply Automated Policy Enforcement and Analysis
Run collected data against predefined policies in real time: flag outputs that violate safety guardrails, detect drift from baselines, identify cost anomalies, and attribute usage by team, model, and application.
Key activities:
- Configure policy rules for safety, compliance, and quality thresholds
- Distinguish between soft alerts (log and review) and hard blocks (enforce at inference time)
- Implement drift detection algorithms that compare current behavior to baselines
- Set cost thresholds that trigger alerts before overruns occur
- Route violations to appropriate stakeholders based on severity
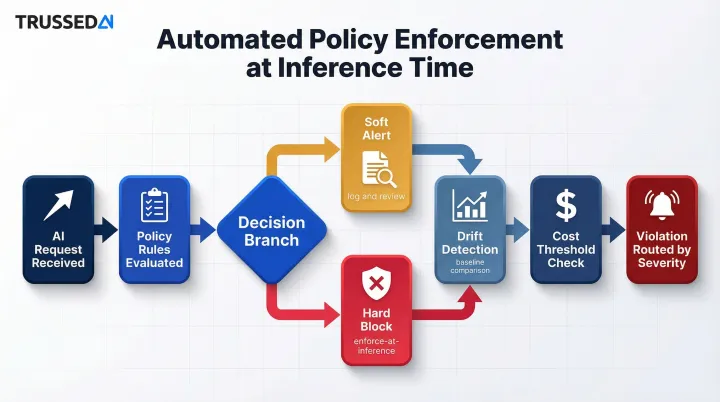
Metrics impacted: Policy violation rate, mean time to detection, cost attribution accuracy.
What teams commonly skip: Treating all alerts equally is how teams stop reading them. A cost anomaly and a safety policy breach are not the same problem,routing them to the same queue, with the same urgency, guarantees that the serious ones get buried.
The EEOC's four-fifths rule provides a concrete threshold for bias monitoring: if the selection rate for any group is less than 80% of the rate for the highest-performing group, adverse impact may exist. Automated policy engines must enforce these thresholds continuously, not just during periodic audits.
Step 5 – Interpret Alerts and Triage Issues
Not every alert requires the same response. Classify findings by severity,safety/compliance, quality degradation, cost anomaly,and route them to the right owners: model teams, compliance officers, or engineering.
Key activities:
- Establish severity definitions: P0 (safety/compliance breach), P1 (quality degradation), P2 (cost anomaly)
- Create routing rules that send P0 alerts to compliance and legal, P1 to model teams, P2 to finance
- Define SLAs for each severity level (e.g., P0 requires 1-hour response)
- Implement escalation paths when alerts aren't acknowledged
- Track alert volume and false positive rates to refine detection rules
Metrics impacted: Mean time to resolution, false positive fatigue, audit finding quality.
What teams commonly skip: Alert triage is an operational problem, not just a tooling problem. The detection layer can be perfect, but if no one owns the incoming queue or the routing rules are vague, findings accumulate unaddressed until they become incidents.
Step 6 – Act, Document, and Refine
Close the loop: remediation actions,prompt updates, model swaps, policy tightening,must be logged with timestamps and outcomes to produce an audit trail. Use each cycle to refine baselines and policies so the system improves continuously.
Key activities:
- Document every remediation action with timestamps, responsible parties, and expected outcomes
- Measure whether remediation resolved the issue (did violations decrease?)
- Update baselines when legitimate changes occur (new model versions, business process changes)
- Refine policies based on false positive analysis
- Generate compliance reports showing issue detection, remediation, and resolution times
Metrics impacted: Recurrence rate of violations, audit-readiness score, governance maturity over time.
What teams commonly skip: Fixing the issue without documenting it is the most expensive shortcut in compliance. When a regulator asks how a specific violation was addressed six months ago, "we handled it" is not an answer - and manual reconstruction from memory and Slack threads takes weeks. Every remediation action needs a timestamped record tied to the original finding.
Key Metrics to Track in a Continuous AI Audit Program
Output Quality and Accuracy
Define task-specific quality metrics,answer relevance scores, factual accuracy, hallucination rates,and monitor them against baselines over time. Quality degradation is often the first symptom of silent model drift.
For customer support copilots, track answer relevance and resolution rates. For document analysis systems, measure extraction accuracy and confidence scores. For code generation tools, monitor compilation success rates and security vulnerability introduction.
When quality metrics drift 10-15% from baseline, investigate immediately. Small degradations compound quickly, and early intervention prevents larger business impact.
Policy and Compliance Violation Rate
Track the percentage of interactions that trigger guardrails or breach defined policies. This metric directly measures governance effectiveness.
For regulated AI applications, acceptable violation thresholds are often defined by law. The EEOC's four-fifths rule provides a concrete threshold for bias monitoring. The CFPB has stated that creditors using complex algorithms must still provide notices disclosing specific reasons for adverse actions,complexity is not a defense for noncompliance.
Platforms like Trussed AI enforce policies at runtime, substantially reducing compliance violations by blocking non-compliant outputs before they reach users rather than detecting them after the fact.
Latency and Availability
Production AI systems must meet SLA commitments. Monitor p50, p95, and p99 latency per model and workflow, and track failover events that indicate reliability gaps.
Average latency tells you little. Tail latency (p95/p99) determines actual user experience. While major cloud providers offer 99.9% uptime SLAs, latency SLAs are rare but now expected. Azure OpenAI offers a 99% latency SLA for token generation on Provisioned deployments, but standard pay-as-you-go endpoints generally guarantee only uptime, not speed.
For multi-step agentic workflows, orchestration overhead compounds latency significantly, making tail latency the critical metric for user-facing applications.
Cost and Usage Attribution
Tracking token consumption and compute spend , by team, model, application, and use case , is essential for budget governance and catching runaway AI usage before it compounds.
Token tracking alone is not enough. Enterprises consistently find that data platform usage, network access and egress fees, and compute overhead rank among the largest unexpected drivers of AI spend — often outpacing raw token costs. Comprehensive cost visibility requires monitoring across the full AI stack:
- Data platform costs: Often the largest surprise expense, regularly outpacing token fees
- Network and egress fees: A significant secondary cost that grows with multi-model and retrieval-augmented architectures
- Compute and orchestration overhead: Compounds in multi-step agentic workflows
Effective cost attribution connects spending to business outcomes, so finance teams can evaluate ROI per use case , and distinguish productive AI investment from waste.
Model and Behavior Drift Indicators
Catch drift early through leading indicators: gradual shifts in output length distributions, increasing guardrail trigger frequency, changes in confidence score patterns. Early detection prevents compounding compliance exposure.
Distinguish between three types of drift:
- Data drift – Changes in input feature distributions
- Concept drift – Fundamental changes in the relationship between inputs and outputs
- Prediction drift – Changes in model predictions over time
Because 91% of models degrade over time, continuous evaluation is required. By the time business impact signals a problem, the compliance exposure has already accumulated.
How Trussed AI Can Help
Trussed AI is an enterprise AI control plane built for continuous performance auditing. Governance isn't added after deployment,it's enforced at runtime, with audit-ready evidence generated automatically as a byproduct of every governed interaction.
The platform covers the complete AI ecosystem,apps, agents, developer tools, and multi-model workflows,through a drop-in proxy that requires zero application code changes. This means organizations can deploy governance across their entire AI infrastructure in weeks rather than months.
Key Capabilities for Continuous Auditing
- Evaluates every AI interaction against defined policies at runtime, blocking non-compliant outputs before they reach users
- Logs each interaction with policy evaluation results, model version, timestamp, and data lineage,so regulators get immediate answers, not weeks of reconstructed evidence
- Tracks spend across teams, models, and applications with attribution tied to business outcomes, with thresholds that trigger alerts or hard stops before overruns occur
- Automatically fails over between providers when models degrade, keeping production AI on SLA commitments
- Shifts governance from point-in-time audits to continuous assurance, significantly reducing manual governance workload
Built for Regulated Industries
These capabilities are backed by built-in controls mapped to HIPAA, GDPR, FERPA, and NIST AI RMF requirements. Enterprises can go from deployment to audit-ready governance workflows rapidly, with no application code changes required.
The result: AI governance that runs continuously in the background rather than demanding manual effort at audit time.
Frequently Asked Questions
What is continuous auditing using AI?
In the context of AI systems, continuous auditing means applying automated, always-on monitoring to model outputs, policy compliance, and performance metrics in production , rather than conducting periodic reviews. It audits the AI itself, not just the business processes AI supports.
Which are strategies for implementing continuous testing with AI?
Key strategies include instrumenting AI calls with a proxy or SDK for full observability, defining policy rules and quality baselines before go-live, automating alert routing to the right owners based on severity, and closing the loop with documented remediation cycles that feed back into policy refinement. Done well, this approach surfaces issues as they occur , not weeks later in a quarterly review.
What are the 4 pillars of ITGC?
IT General Controls cover change management, access controls, computer operations/availability, and physical/logical security. For AI systems, these pillars extend to include model versioning governance, prompt access controls, output monitoring, and compliance controls specific to probabilistic, non-deterministic outputs.
What are the 5 C's in auditing?
The 5 C's are a classic audit reporting framework that maps directly onto AI system auditing:
- Criteria: Expected behavior , baselines and policy definitions
- Condition: Actual outputs , what monitoring data observes
- Cause: Root cause , drift, policy failures, or model degradation
- Consequence: Business impact , cost, compliance risk, quality loss
- Corrective action: Remediation , prompt updates, model swaps, policy changes
How is auditing AI systems different from traditional IT auditing?
Traditional IT audits focus on static configurations, access logs, and control effectiveness , elements that remain constant between review periods. AI system auditing must also account for probabilistic, non-deterministic outputs that change continuously, model drift that degrades performance over time, prompt-level policy enforcement that governs behavior at runtime, and real-time cost governance across dynamic multi-model architectures. The shift from static to continuous is fundamental , AI acts in real time, so governance must operate in real time.


