
Introduction
AI systems now make consequential decisions across regulated industries, including approving credit applications, recommending clinical treatments, and underwriting insurance policies. Yet most organizations cannot answer a simple question: "Where did this data come from, and how did it get here?" When regulators ask how an AI system denied a loan or flagged a medical claim, teams scramble for weeks to reconstruct data flows from fragmented logs and tribal knowledge. The result is a regulatory exposure that compounds with every new AI deployment.
Data lineage is widely discussed as a governance best practice, but its real value shows up in audit outcomes, regulatory examinations, and incident response, not in architecture diagrams. 71% of AI teams cannot produce a complete audit trail for a single AI interaction, which makes retroactive compliance evidence impossible to produce on demand.
Enforcement is already underway globally, and the direction is clear. The Dutch Data Protection Authority fined the Tax Administration €2.75 million for unlawful algorithmic processing, and Sweden fined Klarna Bank approximately €750,000 for failing to explain automated credit decisions. US regulators are watching the same playbook.
What follows covers the concrete operational mechanics of data lineage in AI auditability, including where it fails, why those failures cost organizations, and what working implementation actually looks like.
Key Takeaways
- Data lineage tracks the full journey of data from source through transformation to model output, creating a verifiable record of how AI decisions were made
- The three most impactful advantages are regulatory audit-readiness, explainability for stakeholder trust, and faster root-cause resolution when AI systems produce unexpected results
- Regulated industries face specific compliance obligations under frameworks like GDPR, the EU AI Act, HIPAA, and BCBS 239 , data lineage directly supports each of them
- Without lineage, AI systems operate as black boxes, making incident response reactive and trust in AI outputs difficult to sustain
- Lineage delivers the most value when embedded into AI infrastructure at runtime , not added as an afterthought documentation project
What Is Data Lineage in AI?
Data lineage in AI is a continuously maintained record of where data originates, how it is transformed, which systems it passes through, and how it ultimately feeds AI model inputs and outputs. Unlike a quarterly architecture diagram, it's a living audit trail that captures every data movement as it happens.
In AI contexts, lineage extends beyond traditional data pipelines. It tracks:
- Model versioning - which specific model version processed a request
- Training dataset provenance - what data was used to train the model
- Feature engineering logic - how raw data was transformed into model inputs
- Prediction attribution - which data points influenced a specific decision
When a customer disputes a loan denial, lineage shows exactly which data the AI evaluated, how it was transformed, and which model version made the call.
Data lineage is infrastructure for accountability, not just documentation. Its purpose is to make AI systems explainable when stakeholders demand answers, auditable when regulators investigate, and correctable when something goes wrong. Without it, teams spend weeks reconstructing what should be instantly available.
Key Advantages of Data Lineage for AI Auditability
These advantages reflect operational outcomes that enterprises in regulated industries already track and report on , compliance burden, incident response time, and the defensibility of AI-driven decisions.
Advantage 1: Regulatory Audit-Readiness Without the Manual Scramble
Regulators increasingly require organizations to demonstrate not just what AI systems decided, but what data was used, how it was processed, and whether governance policies were followed. Manual documentation cannot keep pace with this requirement at scale. Financial institutions spend $50 million to $200 million annually on BCBS 239 compliance, much of it on manual data lineage reconstruction.
Continuous data lineage tracking automatically generates the evidence trail regulators require: data source certification, transformation logs, model version records, and policy enforcement history, all timestamped and queryable on demand.
This eliminates the reactive "audit scramble" where teams spend weeks reconstructing data flows from memory or fragmented logs. Automated data lineage and governance tools reduce audit preparation time by 60%–70%, freeing compliance teams to focus on risk management rather than evidence reconstruction.
The advantage connects directly to specific regulatory frameworks:
- EU AI Act (Article 12): High-risk AI systems must automatically record events over the system's lifetime
- EU AI Act (Article 18): Providers must keep technical documentation available for 10 years
- GDPR (Article 30): Controllers must maintain records of processing activities, including AI model training and deployment, per the EDPB
- HIPAA (45 CFR § 164.312(b)): Systems containing ePHI must record and examine activity
- BCBS 239: Complete, up-to-date data lineages required at the attribute level for all risk indicators

Platforms like Trussed AI generate governance evidence as a byproduct of every governed AI interaction, meaning audit trails accumulate automatically rather than requiring dedicated compliance labor.
KPIs impacted:
- Compliance violation rate
- Audit preparation time
- Regulatory penalty exposure
- Manual governance workload
This advantage is highest-stakes in regulated industries where AI drives consequential decisions , loan approvals, clinical triage, insurance claims , and during regulatory examinations or internal audits.
Advantage 2: Explainability That Builds Stakeholder and Customer Trust
Explainability requires more than model interpretability tools. Stakeholders need to trace from a specific AI output back to the exact data that drove it, the transformations applied, and whether that data was certified as reliable and compliant. When a customer is denied a loan, a claim is rejected, or a clinical recommendation is flagged, lineage allows teams to follow the data path backward from decision to source and answer "why did the AI produce this result?"
Data lineage makes this traceability concrete by documenting the complete chain of custody. Teams can show exactly which data points influenced a decision, how those points were transformed, and which model version processed them.
The practical payoff is that AI decisions become defensible across every audience. Compliance officers can satisfy regulatory inquiries, customer service teams can explain outcomes to affected individuals, and executives can stand behind AI-driven decisions in legal or public contexts. 74% of respondents identify AI inaccuracy as a highly relevant risk, and explainability ranks as the second-most-commonly-reported risk, yet organizations rarely mitigate it.
The EU AI Act's Article 13 explicitly requires high-risk AI systems to be designed so their operation is sufficiently transparent to enable deployers to interpret a system's output and use it appropriately. Explainability without lineage is theoretical , lineage is what makes it operational.
The cost of failing to provide explainability is real. IBM's Watson for Oncology recommended unsafe and incorrect cancer treatments because the software was trained with synthetic cases rather than real patient data, leading to major hospital contract cancellations.
KPIs impacted:
- Customer dispute resolution time
- AI decision reversal rate
- Stakeholder confidence scores
- Time required to respond to regulatory inquiries about specific AI decisions
Explainability demand is highest when AI affects individuals directly , credit, healthcare, employment , and when systems operate autonomously at scale with minimal human review at each decision point.
Advantage 3: Faster Root-Cause Analysis and Reduced Operational Risk
In production AI systems, errors compound. A stale data source, a misconfigured transformation, or an undocumented schema change can silently degrade model performance across thousands of decisions before anyone notices. Without lineage, finding the source is guesswork. 68% of data teams need 4+ hours to detect pipeline issues, with average resolution time climbing to 15 hours.
Lineage enables precise upstream tracing. When AI outputs become inconsistent or incorrect, teams can follow the dependency graph backward to identify the exact data source, transformation step, or model version where the error entered the pipeline - without rebuilding logic from scratch.
The operational cost difference between having lineage and not is measured in hours vs. days. With lineage, an engineer pinpoints the affected data batch; without it, the team may need to reprocess entire pipelines and manually audit multiple systems to isolate the problem. Poor data quality costs organizations an average of $12.9 million annually.
Lineage also works forward. Before making a change to a data source, teams can see exactly which downstream models, reports, and decisions will be affected , preventing breaks from ever reaching production. That forward visibility matters: 91% of machine learning models experience degradation over time, and models left unchanged for six months or longer see error rates jump 35% on new data.
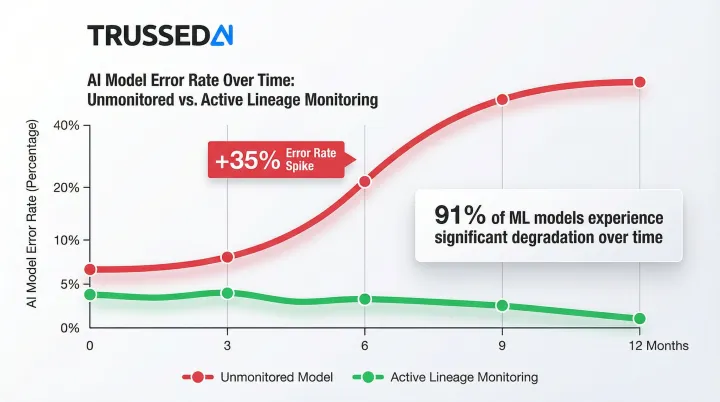
KPIs impacted:
- Mean time to resolve AI incidents
- Pipeline downtime
- Number of downstream assets affected by upstream errors
- Data reprocessing costs
- Model reliability scores
This advantage is most critical when AI pipelines span multiple systems and teams, when models are retrained frequently, and when data assets are shared across multiple AI applications simultaneously.
What Happens When Data Lineage Is Missing from AI Systems
Without lineage, organizations cannot produce the documentation regulators require - turning every examination into a high-risk exercise in reconstruction. Gaps surface, remediation orders follow, and fines compound.
The HHS Office for Civil Rights issued a $240,000 penalty against Providence Medical Institute following a ransomware attack where the entity failed to implement procedures to regularly review records of information system activity.
When AI decisions cannot be explained or traced, internal stakeholders lose confidence in AI outputs. Shadow manual processes fill the gap , duplicating effort and negating the efficiency gains AI was supposed to deliver. 61% of surveyed physicians reported concern that the use of AI by health plans is increasing prior authorization denials, leading to delayed care and increased administrative burden.
Error detection also becomes reactive. Problems surface in business outcomes , anomalous reports, customer complaints , rather than in the pipeline, by which point damage is already widespread. Data scientists and ML engineers spend approximately 40% of their time on "bad data" triage and QA, time that could go toward model development and feature delivery.
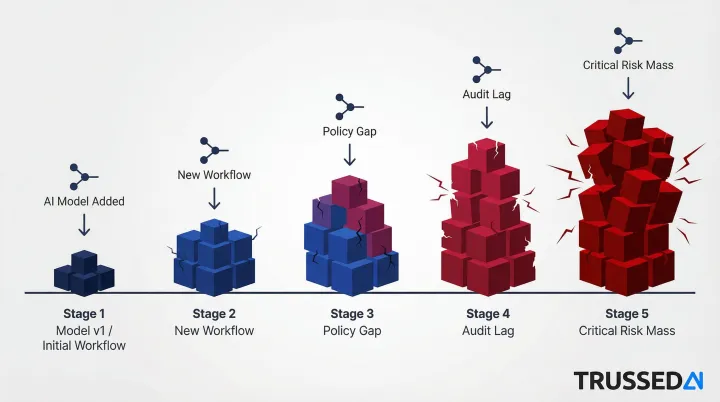
The compounding effect is what makes this dangerous. Each new model, agent, or workflow added without lineage infrastructure deepens governance debt - and retrofitting lineage across a sprawling AI footprint costs significantly more than building it in from the start.
How to Get the Most Value from Data Lineage in AI
Data lineage delivers its full value only when it is captured continuously and automatically , not in periodic documentation sprints. Lineage that is even slightly out of date cannot be trusted for audit purposes or incident response. The EU AI Act mandates that high-risk AI systems technically allow for the automatic recording of events over the lifetime of the system to ensure traceability.
The highest-value implementations treat lineage as a runtime concern, not a post-hoc reporting task. This means every data movement, transformation, and AI interaction is logged at the infrastructure layer, enabling live enforcement and incident response rather than historical reconstruction.
Platforms that operate as a proxy between AI applications and their data and model layers can enforce this without requiring application code changes. Trussed AI's control plane, for example, sits in the flow of AI interactions, capturing policy evaluation results, model versions, timestamps, and data lineage automatically for every interaction.
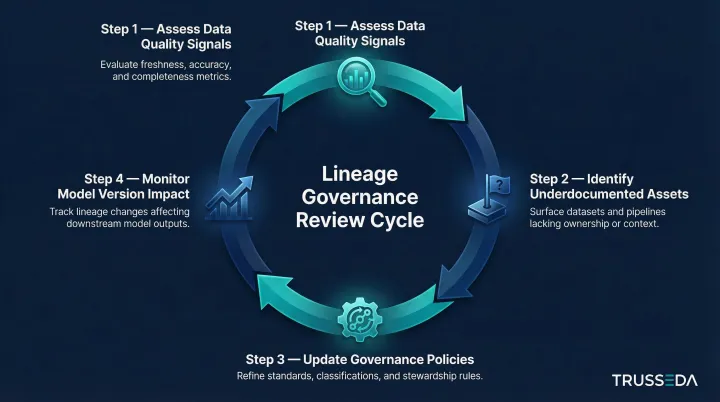
Lineage insights compound over time only when they are acted upon. Teams should establish regular review cadences to:
- Assess data quality signals propagating through the lineage graph
- Identify assets that are heavily consumed but poorly documented
- Update governance policies based on observed data flow patterns
- Monitor model version changes and their impact on downstream decisions
Regulatory frameworks reinforce this approach: NIST AI RMF 1.0 recommends maintaining the provenance of training data and supporting attribution of AI decisions to subsets of training data to assist with transparency and accountability. ISO/IEC 42001 aligns directly , treating traceability and reliability as baseline requirements, not optional features, for organizations managing AI at scale.
Conclusion
Data lineage is the infrastructure that makes AI systems auditable by design , not a compliance checkbox bolted on after deployment. Its advantages in compliance readiness, explainability, and operational resilience compound as AI deployments scale. Organizations in regulated industries that are deploying AI cannot afford to treat lineage as an afterthought; it must be embedded at the infrastructure layer from the start, maintained and enforced at runtime.
Trust in AI is built one traceable decision at a time. When regulators ask how a decision was made, or engineers trace a production failure to its source, lineage determines whether your team answers in minutes or scrambles for weeks. Organizations that embed it from the start turn those moments from crises into routine audits. Those that don't will keep finding out the hard way.
Frequently Asked Questions
What is AI data lineage?
AI data lineage is the continuous, automated record of how data moves from its original source through transformations, pipelines, and into AI model inputs and outputs. It captures not just where data came from, but every step that shaped it before it influenced an AI decision, including model versions and policy enforcement events.
What are the main pillars of data and AI governance?
The core pillars are data quality and provenance, access controls and security, policy enforcement, auditability and lineage tracking, and regulatory compliance. Data lineage ties several of these together , making data flows visible and verifiable so organizations can demonstrate how governance policies applied to specific decisions.
How does data lineage support regulatory compliance for AI systems?
Lineage creates the verifiable evidence trail regulators require under frameworks like GDPR, the EU AI Act, HIPAA, and BCBS 239. It documents data sources, transformation logic, model versions, and policy enforcement events that auditors can review on demand, eliminating manual reconstruction.
How does data lineage enable explainable AI?
Explainability requires traceability , data lineage provides the path from any AI output back to the specific data inputs, feature transformations, and model version that produced it. This allows teams to answer "why did the AI decide this?" with evidence rather than approximation, satisfying both regulatory requirements and stakeholder inquiries.
What happens to AI audit trails without proper data lineage?
Without lineage, audit trails must be reconstructed manually from logs and tribal knowledge, a process that is time-consuming, error-prone, and often incomplete. Organizations are left exposed during regulatory examinations and unable to respond credibly to AI decision inquiries, often resulting in compliance findings or penalties.
How can enterprises automate data lineage tracking in AI systems?
The most effective approach is to enforce lineage capture at the infrastructure layer using a control plane or proxy that logs every data interaction, transformation, and model call automatically. This ensures governance evidence accumulates as a byproduct of normal AI operations rather than manual effort , Trussed AI's drop-in proxy integration does exactly this without requiring any application code changes.


