
The challenge isn't theoretical. 88% of organizations report regular AI use in at least one business function in 2025, yet 15% faced a GenAI security incident in the past year. Most concerning: 97% of organizations reporting an AI-related security incident lacked proper AI-dedicated access controls.
Most guardrail failures don't happen during training or testing,they surface in live interactions, under adversarial conditions, when a real user or agent is on the other end. This is where the question of what actually works becomes consequential.
Key Takeaways
- Runtime guardrails operate during inference, intercepting prompts and inspecting outputs as AI systems interact with users and enterprise data
- Three layers matter: input guardrails (prompt validation), output guardrails (response filtering), and execution guardrails (agent action control)
- ML classifiers are fast but miss novel attacks; LLM-driven guardrails catch subtle intent violations but add latency - production systems typically need both
- Guardrails only function when they sit in the actual execution path - anything else is documentation, not enforcement
What Are Guardrails in Generative AI?
Runtime guardrails are dynamic enforcement controls that evaluate inputs, model behavior, and outputs in real time. Unlike training-time alignment, fine-tuning, or static system prompts that shape model behavior before deployment, runtime guardrails intercept live interactions as they happen.
The non-deterministic nature of LLMs makes guardrails structurally different from traditional application security. The same input can produce different outputs across inference calls. Adversarial inputs are open-ended and adaptive. Violations often emerge gradually across multi-turn conversations rather than in a single detectable event.
That complexity makes a clear taxonomy essential. Two categories of runtime guardrails matter in production:
- Safety guardrails prevent harmful or off-topic content from reaching users,toxicity, bias, hallucinations, and scope drift
- Security guardrails detect and block attacks like prompt injection, data exfiltration, and privilege escalation
Each addresses a distinct failure mode,and in production, you need both running in parallel.

Why Runtime Is the Only Place Guardrails Actually Work
Model-level controls - RLHF, safety fine-tuning, system prompts - establish behavioral tendencies but cannot enforce hard boundaries once a model is in production. Fine-tuning on just 340 adversarial examples successfully removed GPT-4's safety guardrails, demonstrating that training-time alignment can be overridden through prompt manipulation. These controls don't adapt to new attack techniques without retraining.
A policy that doesn't sit directly in the inference loop cannot stop a decision made in milliseconds. AI agents chain actions across systems before a human can intervene. When an agent calls an API, queries a database, or triggers a workflow, the action executes immediately - output filtering applied after the fact cannot undo what's already been done.
That risk compounds at scale. Agentic AI has expanded the attack surface well beyond single-model interactions:
- 40% of enterprise applications will integrate task-specific AI agents by end of 2026, up from less than 5% in 2025
- 50% of organizations already have 10+ agents running in production
- A single compromised instruction in a multi-step workflow can propagate across an entire pipeline
Static controls lose effectiveness as deployments evolve. Early deployments face predictable, bounded risk. But as prompts evolve, integrations expand, and threat actors adapt, static controls degrade. Runtime guardrails must adapt without retraining or redeployment.
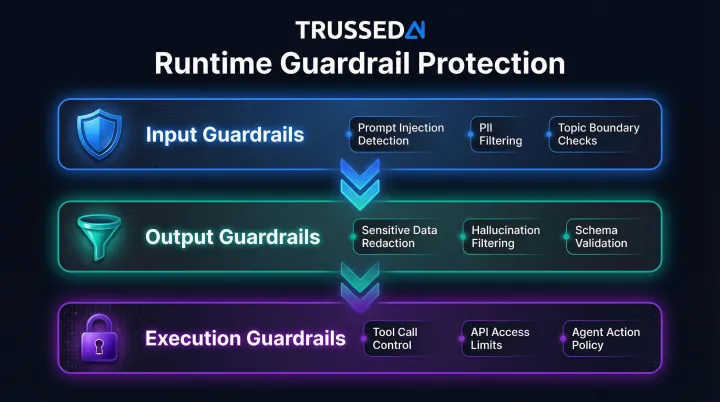
The Three Types of Runtime Guardrails That Work
Effective runtime protection requires coverage at three distinct layers: before the model processes a prompt, after the model generates a response, and around what the model is allowed to do. Teams that only implement one layer have significant blind spots.
Input Guardrails
Input guardrails intercept and evaluate user prompts before they reach the model. They cover:
- Prompt injection detection (flagging known injection prefixes and jailbreak patterns)
- PII filtering (blocking sensitive data from entering the model)
- Input length enforcement (preventing token exhaustion attacks)
- Topic and domain boundary checks (keeping interactions within approved scope)
The combination that works in practice:
- Static regex and keyword filters handle known patterns efficiently
- ML classifiers add signal on common attack categories
- Semantic intent analysis catches obfuscated or indirect injection attempts that pattern-matching misses
Each layer compensates for the weaknesses of the others. Regex filters are fast but brittle; classifiers are more robust but struggle with novel phrasing. Semantic analysis handles the rest , flexible enough for indirect attacks, though slower than the other two.
Output Guardrails
Input controls catch what enters the model. Output guardrails handle what comes back out, applying post-processing to responses before they reach the user. They include:
- Sensitive data redaction (API keys, PII, PHI)
- Domain relevancy checks (catching hallucinations or scope drift)
- Schema validation for structured outputs used by downstream systems
- Toxicity and bias filtering
Output guardrails are the last line of defense against data leakage. Even if a prompt passes input checks, a jailbroken or drifted model can still surface protected information in its response.
OWASP LLM02:2025 (Sensitive Information Disclosure) warns: "LLMs, especially when embedded in applications, risk exposing sensitive data, proprietary algorithms, or confidential details through their output." Real incidents confirm this:
- Microsoft Copilot Chat exposed confidential emails from drafts and sent folders to enterprise users in 2026
- DeepSeek leaked over 1 million log entries , including chat history and API keys , through an exposed database in 2025
Execution Guardrails for Agentic AI
Execution guardrails govern what an AI agent is allowed to do - constraining tool calls, API access, file operations, and inter-agent communications based on least-privilege principles and verified identity. This layer is the most underdeveloped in most deployments. Organizations implement chatbot-level input/output controls but leave tool calls and agentic workflows unguarded, creating an attack surface where prompt injection escalates to real-world system access.
OWASP LLM06:2025 (Excessive Agency) defines this vulnerability as "the vulnerability that enables damaging actions to be performed in response to unexpected, ambiguous or manipulated outputs from an LLM."
Real-world exploitation:
- GitHub Copilot RCE (CVE-2025-53773): Prompt injection embedded in public repository code comments instructed Copilot to modify settings enabling code execution without user approval
- EchoLeak (CVE-2025-32711): A single crafted email sent to a Microsoft 365 Copilot user triggered zero-click, remote data exfiltration without any user interaction
Execution guardrails prevent these attacks by evaluating policy before every tool call, not after output is generated.
Classifier-Based vs. LLM-Driven Guardrails: What Actually Works
Classifier-based (ML) guardrails use purpose-trained models or small language models to detect known risk categories quickly and cheaply. They excel at stable, well-defined threats like toxicity categories, standard PII formats, and signature-based injection patterns. They struggle with novel phrasing, multi-step attacks, and anything requiring contextual reasoning.
Benchmarking data shows OpenAI Moderation API achieved a 0.899 F1 score with 191.5ms latency, while Azure Content Safety achieved a 0.757 F1 score with 52.2ms latency. These classifiers are fast and effective for known threats.
LLM-driven guardrails use a language model to evaluate prompts and outputs against policies expressed in natural language. They can interpret indirect requests, infer intent across multi-turn conversations, and apply nuanced regulatory policies that can't be reduced to a label , but at higher latency and cost. LLM-driven PromptFoo, for instance, lagged with a 0.592 F1 score and 1118.2ms latency.
Both approaches have failure modes that matter in production:
- Classifiers degrade silently as attackers adapt their phrasing
- LLM-driven guardrails can be inconsistent if the evaluating model itself is susceptible to manipulation
- Latency mismatches between classifier and LLM-driven layers can create coverage gaps at high request volumes
The most effective runtime security strategies combine ML and LLM guardrails: purpose-built classifiers block known threats efficiently, while LLM-driven reasoning handles ambiguity and policy nuance. For enterprises in regulated industries, that combination is what makes a guardrail layer defensible under audit.

What Causes Runtime Guardrails to Fail in Production
Over-applying guardrails to conversation history is one of the most common sources of false positives. Evaluating full chat history on every turn means a single blocked topic early in a conversation can prevent legitimate follow-up questions , creating dead ends for users and inflating error rates. Azure OpenAI content filtering has triggered false positive blocks on safe prompts due to conservative thresholds.
Guardrail drift happens when configurations aren't version-controlled or tested against real traffic - and diverge from actual risk conditions over time. Common contributors include:
- Development-mode settings promoted to production without review
- Policy changes that silently weaken enforcement
- Thresholds calibrated on test data that fail under adversarial production inputs
The agentic blind spot is where prompt-level guardrails stop and agent infrastructure begins. Most organizations enforce guardrails on chatbot interfaces but haven't extended that coverage to MCP server calls, tool invocations, or agent-to-agent communication. 36% of AI agent skills contain security flaws , including 1,467 vulnerable skills identified in one study , showing exactly how excessive agency exploits this gap.
Each of these failure modes is preventable, but only if enforcement extends beyond the prompt layer to the full runtime surface.
How to Implement Runtime Guardrails Without Sacrificing Performance
Guardrails that add hundreds of milliseconds to every inference call will be disabled by engineering teams under pressure to ship. Research shows 0.1 seconds is the limit for feeling the system is reacting instantaneously; 1.0 second is the limit for the user's flow of thought to stay uninterrupted.
Three architectural patterns keep guardrails fast enough to stay on:
- NVIDIA NeMo Guardrails running up to five GPU-accelerated checks in parallel increases detection rate by 1.4x while adding only ~0.5 seconds of latency , parallel evaluation avoids the sequential penalty
- Fast ML classifiers can filter obvious violations before invoking more expensive LLM-based reasoning, reserving deep analysis for edge cases
- AWS Bedrock Guardrails evaluates input in parallel for each configured policy, applying selective checks to the most recent turn rather than re-processing full conversation history
Getting to Production Without Breaking Things
- Start in detect-only mode on live traffic to calibrate false positive rates before enabling blocking
- Version-control your guardrail configurations , configuration drift is how policies quietly stop working
- Scope guardrails to the most recent conversation turn in multi-turn sessions, not the full history
As AI deployments expand across models, agents, and application surfaces, each team instrumenting its own controls creates inconsistency and maintenance overhead. The practical answer is a single enforcement layer that applies consistent policy across all AI interactions.
Trussed AI's drop-in proxy addresses this directly: sub-20ms policy enforcement across models and agents, with no changes to application code. The platform intercepts AI interactions at runtime , evaluating tool calls, data access requests, and workflow triggers , so governance applies consistently regardless of which model or environment is running.
Frequently Asked Questions
What are guardrails in generative AI?
Guardrails are real-time controls that enforce safety, security, and policy boundaries during AI inference. Unlike training-time alignment, which shapes model behavior before deployment, guardrails intercept live interactions at the point of execution.
What are the main types of runtime guardrails for generative AI?
Three layers provide runtime coverage:
- Input guardrails , prompt validation and injection detection
- Output guardrails , response filtering and data leak prevention
- Execution guardrails , controlling what agents can do via tool calls and API access
What is AI runtime protection?
AI runtime protection refers to security and governance controls that operate during model inference,the moment a model processes a prompt and generates a response,not controls baked in during training.
How do runtime guardrails differ from training-time guardrails?
Training-time guardrails (like RLHF or safety fine-tuning) shape a model's behavioral tendencies but are overridable at inference. Runtime guardrails actively intercept and evaluate every live interaction regardless of how the model was trained.
Do runtime guardrails add latency to generative AI applications?
Yes, guardrails add processing overhead. Well-architected implementations keep added latency under 20ms for most production deployments. Parallel evaluation, lightweight first-pass classifiers, and efficient proxy designs are the primary techniques that get you there.
What is the difference between classifier-based and LLM-driven guardrails?
Classifier-based guardrails are fast, low-cost ML models optimized for known threat categories. LLM-driven guardrails use a language model to reason about intent and context, making them better suited for novel threats and nuanced policy decisions , at higher latency and cost.


