
Introduction
AI is being deployed faster than governance can keep up. Enterprises across healthcare, financial Solution, insurance, and other regulated industries face a critical challenge: AI systems are moving into production - powering customer experiences, internal tools, and autonomous agent workflows - while governance remains reactive, manual, and fragmented.
The result is measurable exposure. According to IBM's 2025 Cost of a Data Breach Report, organizations with high levels of "Shadow AI" pay an average of $670,000 more in breach costs, and 97% of organizations that experienced AI-related security incidents lacked proper access controls.
This guide covers the essentials for closing that gap:
- What AI guardrails are and why they matter
- The four types enterprises must implement
- Specific threats guardrails protect against
- Real-world examples from regulated industries
- A practical deployment framework with latency benchmarks, integration requirements, and operational best practices
Key Takeaways
- AI guardrails are runtime controls - policies, technical safeguards, and monitoring mechanisms - that govern how AI models behave, keeping outputs safe, compliant, and aligned with business intent
- They operate across four layers - data, model, application, and infrastructure - so no part of the AI stack runs ungoverned
- Without them, enterprises risk prompt injection, data leakage, and regulatory fines reaching 7% of global revenue under the EU AI Act
- Effective guardrails enforce policy at runtime, scale across AI apps and agents, and generate audit evidence automatically
What Are AI Guardrails and Why Do They Matter?
AI guardrails are the safeguards - combining policies, technical controls, and real-time monitoring - that govern how AI models, including LLMs and AI agents, generate outputs and interact with users and data. Think of guardrails on a highway: they don't slow traffic, they prevent it from going off course. In AI systems, guardrails keep models operating within defined boundaries without blocking innovation.
The core problem guardrails solve is the gap between AI innovation speed and governance readiness. As organizations deploy AI into customer experiences, internal tools, and autonomous agent workflows, the attack surface and compliance exposure grows faster than most organizations can manage manually. McKinsey's 2025 State of AI survey found that while nearly nine out of ten organizations regularly use AI, only about one-third report maturity levels of three or higher in governance strategy.
That governance gap has a direct price tag. Under the EU AI Act, non-compliance with prohibited AI practices carries fines up to €35 million or 7% of total worldwide annual turnover,whichever is higher. For violations of operational requirements like logging and record-keeping, penalties reach €15 million or 3% of global revenue. GDPR violations can add another €20 million or 4% of annual turnover, while HIPAA penalties in the U.S. reach $1.5 million per violation category annually.
Effective AI guardrails require dynamic enforcement at runtime,across every interaction, dataset, workflow, and agent an enterprise deploys. The EU AI Act makes this explicit in Articles 12 and 19, mandating automatic runtime logging with minimum six-month retention for high-risk systems. Static policy documents and one-time model configurations don't meet that bar. Compliance now demands continuous runtime enforcement.
Key business benefits guardrails deliver:
- Accelerate AI deployment without sacrificing oversight or safety
- Regulatory alignment with GDPR, HIPAA, EU AI Act, and industry frameworks
- Reduced breach costs through proactive data protection
- Stronger stakeholder trust through transparency and accountability
- Predictable AI outputs that hold up under enterprise performance requirements
The Four Types of AI Guardrails
AI guardrails operate at four distinct layers of the AI stack: data, model, application, and infrastructure. This framework aligns with standards from NIST AI RMF 1.0 and ISO/IEC 42001, ensuring coverage across the entire AI lifecycle. AI governance acts as the overarching foundation that connects all four layers to responsible AI principles.

Data Guardrails
Data guardrails protect the inputs that AI models are trained and grounded on - removing PII, reducing bias, enforcing data privacy rules, and validating training data quality. Without clean, curated data, model outputs will inherit those flaws at scale.
For regulated industries, data guardrails are non-negotiable. Healthcare organizations must prevent PHI from entering training pipelines under HIPAA's technical safeguards (45 CFR 164.312). Financial institutions must ensure training data doesn't encode discriminatory lending patterns that violate fair lending laws. Universities must protect student records under FERPA (34 CFR Part 99).
Data guardrails include:
- PII detection and redaction at data ingestion and runtime
- Bias detection in training datasets
- Data quality validation before model training
- Access controls limiting who can use sensitive data for AI development
- Data lineage tracking to maintain chain of custody
Model Guardrails
Model guardrails govern AI model behavior through fine-tuning, alignment techniques (such as RLHF or Constitutional AI), continuous monitoring, and performance metrics like toxicity scores, accuracy, latency, and robustness benchmarks.
Model guardrails also include behavioral drift detection,monitoring whether a model's outputs shift over time in production. For long-running enterprise deployments, drift can indicate data quality degradation, adversarial manipulation, or unintended learning from production interactions.
Key model guardrail controls:
- Alignment and fine-tuning to embed safety constraints
- Performance benchmarking against accuracy, latency, and reliability targets
- Toxicity and bias scoring for generated outputs
- Drift detection to identify behavioral changes over time
- Version control to track which model version produced which output
Application Guardrails
Application guardrails are the runtime controls embedded at the interface between users and AI,including API-level policy enforcement, input validation, output filtering, content moderation, and topic restrictions that define what an AI app can and cannot do.
They operate at two control points: inputs are validated and sanitized before the model processes a request, while outputs are reviewed and filtered before reaching the user.
| Control Point | What It Does |
|---|---|
| Input guardrails | Block adversarial prompts, filter PII, enforce topic restrictions |
| Output guardrails | Redact sensitive data, block harmful content, flag hallucinations |
Application-layer controls include:
- Prompt injection detection to block adversarial inputs
- PII redaction in both inputs and outputs
- Content moderation for toxicity, hate speech, and misinformation
- Topic restrictions to keep AI assistants on-domain
- Rate limiting to prevent abuse and manage costs
Infrastructure Guardrails
Infrastructure guardrails provide the secure foundation for AI workloads: access controls, encryption, network segmentation, audit logging, and monitoring at the cloud or on-premises layer.
This layer is most consequential for enterprises running AI across hybrid or multi-cloud environments, where enforcing consistent policy across deployments is operationally complex without a centralized control mechanism. When application-layer controls fail or are misconfigured, infrastructure guardrails are what prevent a policy gap from becoming a compliance incident.
Infrastructure controls include:
- Identity and access management (IAM) with role-based access controls
- Encryption at rest and in transit for model weights and training data
- Network segmentation to isolate AI workloads
- Audit logging with immutable records of all AI interactions
- Cloud security posture management for multi-cloud AI deployments
What Threats Do AI Guardrails Protect Against?
AI guardrails defend against four threat categories that target the specific vulnerabilities of AI systems: prompt injection and jailbreaks, sensitive data exposure, harmful and biased content, and unpredictable model behavior.
Prompt Injection and Adversarial Attacks
Prompt injection is the most prevalent AI-specific attack vector. Cisco's 2026 State of AI Security found prompt injection weaknesses in 73% of audited production AI deployments. Palo Alto Networks Unit 42 linked indirect prompt injection to credential or payment-data exposure in 18% of investigated AI security incidents.
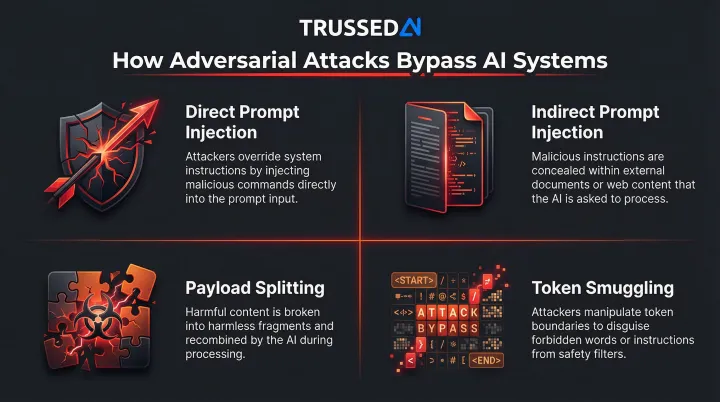
How adversarial attacks work:
- Direct prompt injection: User input overrides system instructions or safety filters, redirecting model behavior outside intended boundaries
- Indirect prompt injection: Hidden instructions embedded in websites, uploaded files, or RAG-retrieved documents silently hijack model responses
- Payload splitting: Malicious instructions are fragmented across multiple inputs, then assembled by the model during processing - evading per-input filters
- Token smuggling: Inputs are crafted to exploit tokenization patterns, bypassing filters by steering the model's next-token predictions
CrowdStrike's 2026 Global Threat Report documented adversaries exploiting legitimate GenAI tools at more than 90 organizations by injecting malicious prompts to generate commands for stealing credentials and cryptocurrency.
Sensitive Data Exposure
AI models can inadvertently expose PII, PHI, financial records, or proprietary data through outputs , either because the data appeared in training sets or was retrieved via RAG systems. Without output guardrails, an AI assistant might surface another customer's account details, or a clinical documentation assistant might leak patient information across sessions.
Shadow AI compounds the risk significantly. Employees using unsanctioned AI tools bypass any guardrail controls entirely. Gartner predicts that by 2030, more than 40% of enterprises will experience security or compliance incidents linked to unauthorized Shadow AI. IBM found one in five organizations already reported a breach due to Shadow AI , yet only 37% have policies to detect or manage it.
Harmful and Biased Content
Without content moderation guardrails, enterprise AI systems can produce outputs that create direct legal and reputational exposure:
- Generate hate speech or discriminatory language in customer-facing interactions
- Reinforce bias in high-stakes decisions such as hiring, lending, or insurance underwriting
- Hallucinate factual claims that trigger liability in regulated or advisory contexts
Unpredictable Model Behavior
Even well-trained models can produce unexpected completions that create liability. Agentic AI systems amplify this risk: agents don't just generate text, they call tools, query databases, trigger workflows, and take actions across systems. Output filtering doesn't help when the risk isn't what the model says,it's what the agent does next.
AI Guardrails in Action: Examples Across Regulated Industries
Regulated industries are successfully deploying AI by mapping runtime guardrails directly to existing compliance frameworks. Here's how guardrails are applied in healthcare, financial Solution, and higher education:
Healthcare: Clinical Documentation and Patient Support
Healthcare organizations deploy AI for clinical documentation assistants, medical research tools, and patient support automation,all requiring strict governance around PHI. HIPAA's technical safeguards (45 CFR 164.312(b)) require mechanisms that "record and examine activity in information systems that contain or use electronic protected health information."
Mayo Clinic's AI governance model employs audit logs and explainability tools to deploy imaging AI, resulting in 95% clinician trust scores while maintaining full HIPAA compliance. The common pattern: guardrails enforce policy at runtime (blocking PHI leakage, validating clinical decision logic), while generating audit evidence automatically as a byproduct of every governed interaction.
Financial Services: Compliance and Supervision
FINRA Rule 3110 and SEC Rule 17a-4 require broker-dealers to supervise AI-generated communications and retain them as business records. FINRA Notice 24-09 states that firms using GenAI for supervisory systems must ensure "its policies and procedures should address technology governance, including model risk management, data privacy and integrity, reliability and accuracy of the AI model."
Financial institutions deploy guardrails across contract analysis, fraud detection, and underwriting through three mechanisms:
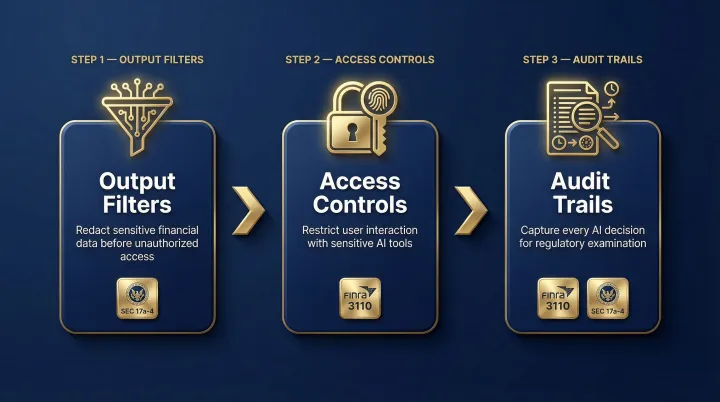
- Output filters redact sensitive financial data before it reaches unauthorized users
- Access controls limit which users can interact with sensitive AI tools
- Full audit trails capture every AI decision for regulatory examination
Higher Education: Student Privacy and Research
Universities must protect student records under FERPA while enabling AI access for research and administration. One Ivy League university deployed an on-premise AI governance platform to ensure no student data is transmitted to external AI Solution, achieving 100% FERPA compliance. Topic restrictions keep student-facing AI tools on-domain, PII filters prevent accidental disclosure, and role-based access controls limit which faculty and staff can access sensitive AI capabilities.
The common pattern across these examples: Guardrails must be enforced at runtime, not just at the point of model selection or deployment. Enterprises that succeed treat guardrails as operational infrastructure: always active, continuously logging, and updated as policies evolve,not a configuration step performed once at launch. Audit trails, compliance logs, and policy violation records aren't optional documentation. Regulators require them.
How to Implement AI Guardrails at Enterprise Scale
Implementing AI guardrails at enterprise scale requires a three-layer approach: policy definition, runtime enforcement, and continuous monitoring. Together, these layers turn static compliance requirements into operational controls that hold across models, agents, and workflows.
Policy Definition: Translating Compliance into Enforceable Rules
Start by mapping compliance requirements and business rules into enforceable guardrail policies. The translation looks different by industry:
- Healthcare (HIPAA): Block PHI in outputs, enforce role-based access, log every interaction with patient data
- Financial Solution (FINRA): Capture AI-generated communications, validate model outputs before they reach customers
- Higher education (FERPA): Restrict student record access by role, audit AI interactions involving enrollment data
Policies should be defined once and enforced continuously across all AI systems. This requires a centralized policy engine that integrates with identity providers (Okta, Azure AD) for RBAC enforcement and supports policy-as-code frameworks so compliance teams can update rules without redeploying applications.
Runtime Enforcement: Applying Policies at the Point of Execution
Runtime enforcement is where guardrails move from policy documents to active controls. Every AI interaction , a chatbot response, an agent tool call, a developer query , gets evaluated against policy before it executes.
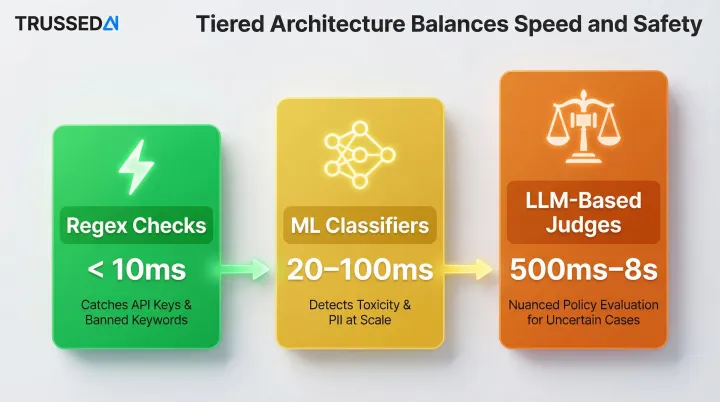
The latency-vs-safety tradeoff is real, but manageable through tiered architecture:
- Regex checks (<10ms): Catch API keys and banned keywords immediately
- ML classifiers (20–100ms): Detect toxicity and PII at scale
- LLM-based judges (500ms–8s): Handle nuanced policy evaluation only for uncertain cases
NVIDIA NeMo benchmarks show that orchestrating up to five GPU-accelerated guardrails in parallel adds only ~0.5 seconds of latency, delivering 50% better protection without meaningfully slowing responses.
Proxy-based enforcement sits outside the application layer, intercepting API calls before they reach models. This architecture enables zero-code integration: applications route requests through the guardrail proxy without modification, centralizing enforcement across all AI systems.
Continuous Monitoring: Logging, Feedback, and Refinement
Guardrails must log every governed interaction to create audit trails and surface policy violations. Each interaction should be captured with policy evaluation results, model version, timestamp, and data lineage , giving organizations a complete chain of custody from prompt to model to output to action.
Continuous monitoring also requires managing false positives (safe prompts incorrectly blocked) and false negatives (harmful outputs slipping through). Balancing this tradeoff requires ongoing calibration through red-teaming, adversarial testing, and structured feedback loops. NIST AI 600-1 recommends organizations "perform AI red-teaming to assess resilience against abuse to facilitate attacks."
Integration Requirements for Enterprise Deployment
Enterprise-scale guardrail deployment requires integration with existing infrastructure:
- Identity provider integration (Okta, Azure AD) for RBAC enforcement using SCIM 2.0 for user provisioning and OAuth 2.0/OIDC for authentication
- Observability stack integration using OpenTelemetry Protocol (OTLP) for telemetry data, with native support from platforms like Datadog and Splunk
- Policy-as-code frameworks that allow compliance teams to update rules without redeploying applications
- API gateway compatibility to enforce guardrails at the network edge
Trussed AI addresses these implementation challenges as a drop-in control plane: a proxy-based architecture that enforces guardrails in real time with zero changes to existing application code, automatic audit trail generation as a byproduct of every governed interaction, and a unified policy layer that spans AI apps, agents, and developer tools , built specifically for the compliance and operational demands of regulated industries.
Frequently Asked Questions
What do guardrails mean in AI?
AI guardrails are the policies, technical controls, and monitoring mechanisms that keep AI systems operating safely and within defined boundaries. They govern how models generate outputs, access data, and interact with users,enforcing rules at runtime to prevent harmful behavior, data leakage, and compliance violations.
What are the four general types of guardrails?
The four types each operate at a distinct layer of the AI stack:
- Data guardrails - protect training and input data
- Model guardrails - govern model behavior and performance
- Application guardrails - enforce runtime controls at the user interface
- Infrastructure guardrails - secure the underlying cloud or on-premises environment
What are examples of AI guardrails?
Common examples include:
- Input validation that blocks prompt injection attempts
- Output filters that redact PII before responses reach users
- Topic restrictions that keep customer service bots on-domain
- Access controls that limit which users can interact with sensitive AI tools
- Audit logging that captures every AI interaction for compliance reporting
What role do guardrails play in responsible AI?
Guardrails are the operational mechanism through which responsible AI principles,fairness, safety, transparency, and compliance,are actually enforced at runtime. They turn policy commitments into real-world controls on every AI interaction, ensuring models behave as intended and organizations can demonstrate governance to regulators and auditors.
How do AI guardrails work in agentic AI systems?
Agentic AI introduces unique guardrail challenges because agents take sequences of actions with real-world consequences. Guardrails for agents must govern multi-step workflows, tool calls, and autonomous decisions , not just individual model outputs. That means runtime policy enforcement at every action step, not only at the input/output boundary.
What is the difference between input guardrails and output guardrails?
Input guardrails validate and filter what enters the model, blocking adversarial prompts, sanitizing PII, and enforcing topic restrictions before the model processes the request. Output guardrails review and filter what the model returns before it reaches the user, redacting sensitive data, blocking harmful content, and flagging hallucinations or policy violations.


