
Introduction
AI models degrade, drift, and accumulate technical and regulatory debt over time. In production, the risks are concrete: data distributions shift, regulatory frameworks evolve, and user behavior changes in ways that erode model reliability.
Without structured oversight, the models making critical decisions across your enterprise can fail silently , and by the time anyone notices, the damage is done.
Undetected drift leads to inaccurate outputs affecting real business decisions. Shadow AI , models running in production that governance teams don't know about , compounds that risk with every interaction. Shadow AI incidents cost an average of $670,000 more than standard security breaches, and by 2030, more than 40% of enterprises will face security or compliance incidents linked to unauthorized AI systems.
Reactive fixes are far more expensive than proactive governance. £27.7 million in FCA fines for trading algorithm failures and $2.7 million in CFPB penalties for a faulty savings algorithm illustrate what unmanaged model debt costs in regulated environments.
This guide covers:
- Why AI model lifecycle governance matters
- The types of governance activities required at each lifecycle stage
- Early warning signs that models need attention
- A practical oversight schedule that grows with your AI portfolio
Key Takeaways
- AI models degrade through data drift, concept drift, and shifting regulations,governance requires continuous oversight, not a one-time deployment check
- Four governance types work in layers,from continuous monitoring and corrective intervention to predictive analytics and full lifecycle reviews
- Key warning signs: accuracy drops, cost spikes, repeated policy violations, and failed compliance audits
- Tiered governance schedules,daily through annual,should scale to each model's risk level
- Platforms that enforce policy at runtime reduce manual workload and generate compliance evidence automatically
Why AI Model Lifecycle Governance Matters
AI model lifecycle governance is not a compliance checkbox but an operational discipline spanning development, deployment, monitoring, and retirement. It ensures every model in production is known, owned, and performing as intended. This matters because organizations commonly run models in production that governance teams are completely unaware of,shadow AI that creates invisible risk. 80% of workers use unapproved AI tools, and 86% of organizations lack visibility into these data flows, creating exposure that governance frameworks cannot address if they don't know the models exist.
Performance risk builds from the earliest lifecycle stages. Decisions made during data selection and training cascade through every subsequent stage - bias introduced upstream amplifies as models make more decisions downstream. Models trained on historical data also become unreliable as the world changes around them. 91% of machine learning models degrade over time, sometimes abruptly, even when underlying data appears stable.
Regulatory exposure makes reactive governance untenable. Three major frameworks now impose specific lifecycle controls on high-risk AI systems:
- EU AI Act , requires six-month log retention and 15-day incident reporting for high-risk systems
- NIST AI RMF , mandates risk identification, measurement, and management across the full model lifecycle
- ISO/IEC 42001 , establishes auditability and accountability requirements for AI management systems
Organizations in insurance, healthcare, and financial Solution face compounding exposure from both failed models and failed governance records. Proactive lifecycle governance is far less costly than incident response or regulatory penalties after the fact.

Types of AI Model Lifecycle Governance
Model lifecycle governance is not one-size-fits-all. Different stages require different governance postures, from ongoing monitoring to deep revalidation. Matching the right governance type to the right trigger separates sustainable programs from those that collapse under delivery pressure.
Continuous (Proactive) Governance
Continuous governance is the baseline layer: real-time policy enforcement across every model interaction, automated drift monitoring, access controls, and audit trail generation. This governance activity runs at all times, regardless of whether a problem has been detected.
Typical activities include:
- Policy enforcement at inference time, validating every request against defined rules
- Latency and performance threshold checks to catch degradation early
- Cost attribution tracking across teams, models, and applications
- Automatic logging of every governed interaction with full context
Platforms like Trussed AI enforce these controls at runtime via a drop-in proxy, generating compliance evidence as a byproduct of production traffic rather than as a separate manual process. This approach makes continuous governance operationally sustainable as AI portfolios scale.
Corrective (Reactive) Governance
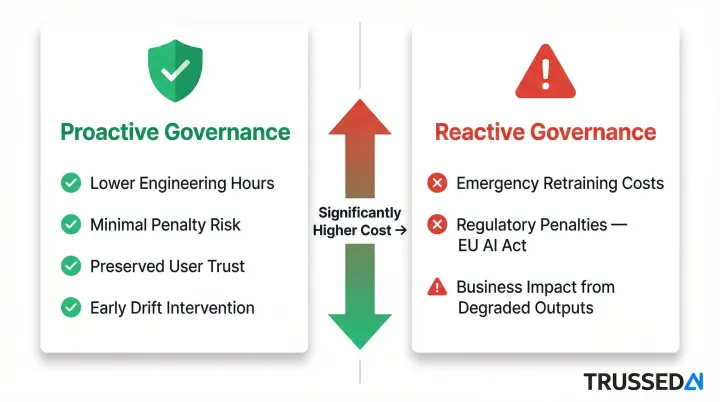
Reactive governance is triggered by a failure event: a drift threshold breach, a compliance violation flag, an audit failure, or an anomalous output pattern. It answers the question "what went wrong and how do we fix it?" The challenge is that relying on this as the primary governance mode is high-risk , problems are already affecting users or regulators before intervention begins.
Reactive remediation is far more expensive than proactive intervention. Organizations that wait for failures to trigger governance action absorb costs across three fronts:
- Direct remediation: emergency retraining and rushed revalidation
- Regulatory exposure: penalties and response documentation under frameworks like the EU AI Act
- Business impact: degraded model performance affecting users and decisions before any fix is deployed
Catching drift before it crosses a threshold is measurably cheaper , in engineering hours, penalty risk, and user trust , than responding after a compliance incident.
Predictive Governance
Predictive governance is data-driven early intervention: using performance trend data, anomaly detection, and usage pattern analysis to identify models approaching a degradation or compliance threshold before they breach it. This differs from simple monitoring by emphasizing forward-looking indicators over backward-looking alerts.
Typical activities include:
- Tracking Mean Time to Detect (MTTD) metrics to understand how quickly problems surface
- Setting automated retraining triggers based on drift velocity rather than crossed thresholds
- Using performance forecasting to schedule validation before problems emerge
- Analyzing usage patterns to predict which models will hit capacity or cost limits
This governance type requires infrastructure that captures trend data continuously and surfaces it in actionable formats, enabling teams to intervene before thresholds are breached.
Full Lifecycle Review (Overhaul Governance)
Full lifecycle review is periodic deep governance: comprehensive revalidation against updated regulatory requirements, full bias and fairness audits across protected groups, architecture reassessment, and formal retirement eligibility evaluation. This is not triggered by a failure but by time or a defined risk tier milestone.
It is required when:
- Major regulatory framework updates occur (such as EU AI Act tier reclassification)
- Significant shifts in training data distribution are detected
- Model succession planning dictates evaluation of replacement options
- Cumulative corrective interventions indicate the model's fundamental assumptions may no longer hold
Full reviews are resource-intensive but essential. They catch what daily monitoring misses: structural problems, accumulated technical debt, and misalignment with evolved business requirements.
Signs Your AI Models Need Lifecycle Attention
Governance programs that catch warning signs before they become production incidents protect both model reliability and regulatory standing. These signals apply across model types, from traditional ML to generative AI and agentic systems.
Performance and Output Degradation
Declining prediction accuracy, output inconsistency against baselines, and task completion failures all indicate that a model's learned assumptions are diverging from current reality. The mechanism varies: data drift means the input distribution has shifted, while concept drift means the relationship between inputs and outputs has changed.
These signals tend to emerge gradually. Without continuous measurement against established baselines, degradation builds unnoticed until it reaches business outcomes.
Policy Violations and Guardrail Triggers
Rising frequency of policy violations,content guardrail activations, data handling flag events, access control anomalies,is an early indicator that a model's behavior is drifting outside its governed boundaries, even before downstream performance metrics degrade.
In agentic AI systems, policy violations can cascade across workflows, making early detection at the inference layer critical. 88% of organizations with active AI agents report confirmed or suspected security incidents, rising to 92.7% in healthcare, where a single compromised agent can poison downstream decision-making within hours.
Increased Latency, Cost, and Resource Consumption
The following operational signals often precede quality degradation , each indicates a model working harder for the same outputs:
- Rising inference latency beyond established thresholds
- Unexpected cost spikes in token usage or compute spend
- Increasing retry rates or fallback events at the inference layer
Real-time cost attribution across models and teams surfaces these patterns early. Without it, overruns build unchecked and teams have no way to connect spending to specific model behavior.
Recurring Compliance Failures and Audit Gaps
Repeated compliance findings,missing audit trail entries, undocumented model versions in production, failed bias checks during periodic review,point to a governance infrastructure problem, not just a model problem.
For organizations under HIPAA, the EU AI Act, or financial Solution regulations, incomplete lifecycle records create compounding exposure: the model failure and the documentation failure become two separate compliance findings, each requiring its own remediation track.
AI Model Lifecycle Governance Schedule
Tier governance schedules by model risk. High-risk models serving critical decisions in healthcare, finance, or regulated workflows require higher-frequency oversight than lower-risk models. A flat schedule creates a real problem: it over-governs low-risk models or leaves high-risk ones under-supervised. Calibrate the framework below to your organization's risk tier definitions.
Governance Frequency Framework
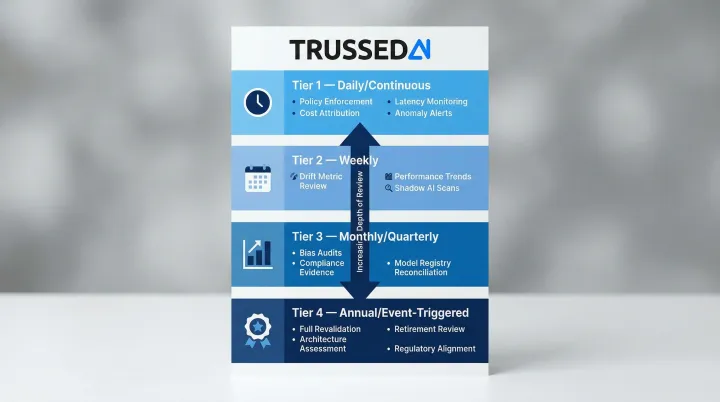
Daily / Continuous:
- Real-time policy enforcement log review
- Latency and error rate monitoring against SLA thresholds
- Cost attribution tracking per model and team
- Anomaly and guardrail trigger alerts
Weekly:
- Drift metric review (data drift and prediction drift indicators)
- Performance trend analysis against baseline
- Shadow AI detection scan for ungoverned model activity
Monthly / Quarterly:
- Bias and fairness audit across protected groups
- Compliance evidence package generation for regulatory reporting
- Model registry reconciliation to confirm all production models are inventoried and owned
- Formal performance review against original validation benchmarks
Annual / Event-Triggered:
- Full model revalidation against current regulatory framework requirements
- Architecture and successor model assessment
- Retirement eligibility review for models with persistent corrective intervention history
- Regulatory alignment update (EU AI Act, NIST AI RMF, ISO/IEC 42001 controls mapping)
Manual execution of this schedule becomes unsustainable as AI portfolios grow. At scale, teams cannot retrospectively reconstruct audit evidence across dozens or hundreds of production models without significant overhead. Governance platforms that generate evidence automatically at runtime make this schedule operationally viable , without adding headcount to sustain it.
Conclusion
AI model lifecycle governance is essential operational infrastructure, not optional compliance overhead. Models that perform brilliantly at launch will silently degrade without structured oversight, and the cost of reactive intervention far exceeds the cost of proactive governance. The AI governance software market is projected to reach $15.8 billion by 2030 because organizations recognize that unmanaged AI portfolios represent critical regulatory and financial liability.
The right approach balances governance intensity with model risk: continuous enforcement as the baseline, corrective intervention as the exception, and periodic full reviews to catch what daily monitoring misses.
Organizations that embed governance into runtime operations, rather than layering it on as a separate process, scale AI with far greater confidence. Platforms like Trussed AI demonstrate this in practice - enforcing policies at runtime through a drop-in proxy, turning static governance documents into active controls that generate compliance evidence automatically.
A structured lifecycle governance plan , with clear schedules, defined ownership, and automated evidence generation , is the difference between an AI portfolio that drifts toward risk and one that stays production-ready as it scales.
Frequently Asked Questions
What is an AI model governance platform?
An AI model governance platform is infrastructure that centralizes oversight of AI models across their full lifecycle, covering policy enforcement, compliance monitoring, audit trail generation, and model registry. It enables organizations to deploy AI responsibly at scale by automating governance controls that manual processes cannot sustain.
What is AI lifecycle governance?
AI lifecycle governance is the set of policies, controls, and oversight activities applied to an AI model from development through retirement, ensuring it remains accurate, compliant, and aligned with its intended use at every stage. Unlike traditional software, models require continuous management,performance degrades, data distributions shift, and regulatory requirements evolve over time.
What are the stages of the AI model lifecycle?
The core stages are development, training operationalization, deployment, prediction serving, monitoring, and retirement. Governance requirements differ at each stage: deployment focuses on policy enforcement and access controls, monitoring emphasizes drift detection and performance tracking, and retirement demands formal documentation and stakeholder sign-off.
How do you detect model drift in production?
Model drift detection requires continuous monitoring of performance metrics against established baselines, with automated alerts when thresholds are exceeded. Data drift tracks input distribution shifts and acts as an early warning signal; concept drift detects changes in the input-output relationship and directly impacts accuracy, requiring immediate intervention.
When should an AI model be retired or replaced?
Retire a model when accuracy degradation cannot be corrected through retraining, when regulatory non-compliance cannot be remediated, when a superior replacement is available, or when the business use case ends. Retirement requires the same governance rigor as deployment: document the decision, notify stakeholders, and confirm downstream systems are updated.


